

Una delle attività più time consuming nelle aziende, a prescindere dalle dimensioni e dal core business delle stesse, è la ricerca di informazioni chiave all’interno di grandi quantità di documenti, spesso di grandi dimensioni e nei formati più disparati (.pdf, .doc, .xls e/o altri formati proprietari). Immaginiamo, ad esempio, la necessità di recuperare una particolare clausola di un contratto stipulato con un fornitore, o di riassumere in poche righe i punti principali di un allegato tecnico, o la ricerca di un passaggio chiave in una procedura di installazione, soprattutto nei casi in cui queste informazioni sono “affogate” in cartelle o sistemi documentali che contengono centinaia di files di grandi dimensioni. Attività che, di norma, necessita di qualche ora di lavoro di ricerca, raffinamento, estrazione delle informazioni e generazione di un riassunto da poter inviare via e-mail al collega o riportare in un altro documento. La problematica può essere ulteriormente estesa anche alla ricerca all’interno di log di sistema, transcript di chat o conversazioni del call center o del backoffice, fino ad arrivare all’analisi dei Social Media Trends, attività che coinvolgono elevate quantità di dati testuali. La tecnologia dei Large Language Models che abilita la Generative AI ha dato risultati sorprendenti sul tema della Search and Summarization, e molti Use Cases raccolti con le strutture aziendali sono riconducibili al pattern architetturale relativo alla ricerca basata su NLP (Natural Language Processing). Utilizzando in modo opportuno le diverse tecnologie è possibile fornire al motore di Generative AI, tramite un’interfaccia di tipo conversazionale, un prompt in linguaggio naturale unitamente ai riferimenti della location dove sono storicizzati i documenti. Il motore risponde con il miglior completamento possibile del prompt stesso, che nel caso in questione corrisponde alla sintesi o elaborazione delle informazioni ricercate in uno o più documenti e, ove richiesto, i riferimenti ai capitoli dei documenti stessi. L’architettura di riferimento prevede, per questa tipologia di use case, l’istanziazione di un singolo stack applicativo che soddisfi esigenze provenienti da strutture diverse (es. multi-tenancy), possibilmente agnostico rispetto alla tecnologia utilizzata e compatibile con aggiornamenti successivi del modello LLM sottostante (es. GPT-4 vs GPT3.5), così come rappresentata in Fig.A.
L’architettura si compone dei seguenti moduli logici:
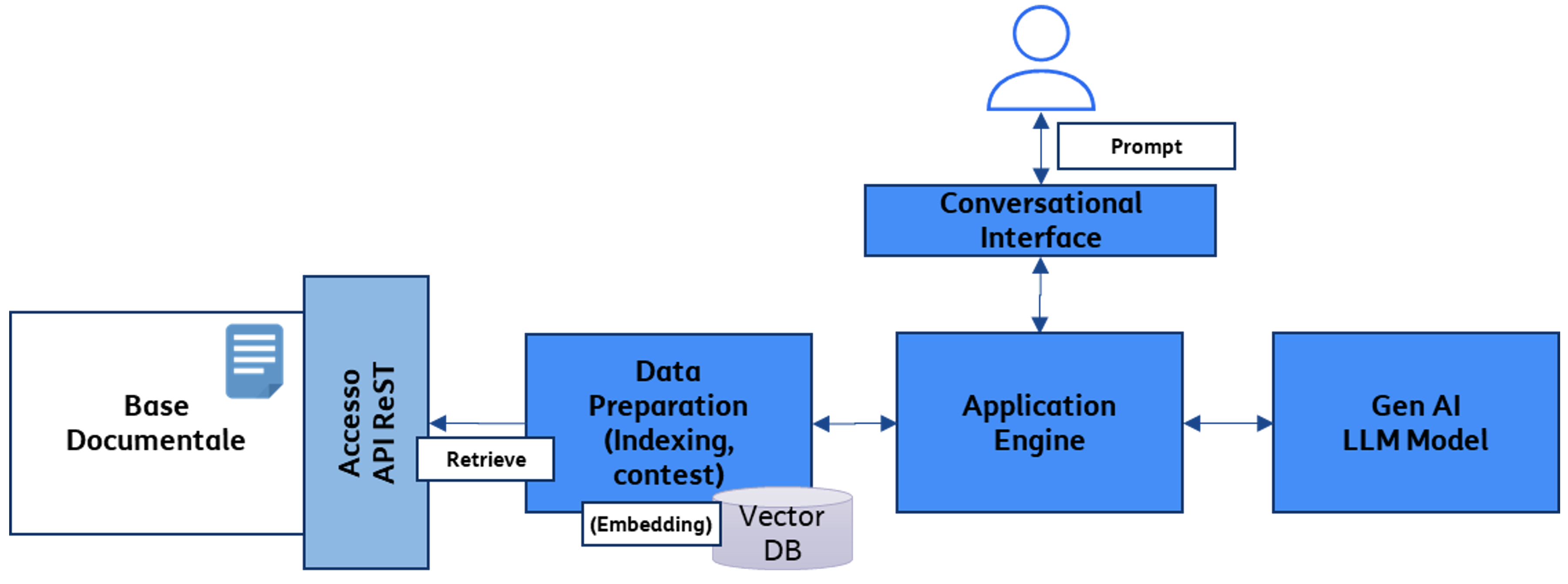
Figura A: Architettura di riferimento per applicazioni di Search & Summarization
Nel disegno architetturale è necessario approntare alcuni accorgimenti: uno dei problemi principali è la tokenizzazione dei contenuti, in quanto i motori LLM hanno una limitazione intrinseca del contesto, in termini di numero massimo di token da fornire al modello insieme al prompt di domanda. La conformazione del token varia in base alla tecnologia (ad esempio Open AI utilizza una codifica BPE -Byte-Pair encoding- che corrisponde all’incirca ad una sillaba di una parola) e alla frequenza di occorrenza della coppia di caratteri o byte. Di seguito si elencano alcuni dei metodi utilizzati per passare il contesto (documento tokenizzato e prompt) al modello:
Un altro strumento estremamente potente utilizzabile in questo ambito è l’Embedding, ovvero una rappresentazione vettoriale di un testo. Tale rappresentazione fornisce capacità avanzate di “Semantic Search & similarity”. Utilizzata come input al modello generale LLM permette di creare applicazioni di Search & Summarization documentale specifica su basi dati private come ad esempio repository di contratti, documenti aziendali, manuali di grandi dimensioni, mantenendo il contesto dati circoscritto al perimetro aziendale. Il principio di base è la rappresentazione dei documenti stessi, dei metadati associati ad essi e di altri possibili dati ausiliari tramite uno spazio vettoriale, inteso come vettori numeri in virgola mobile. L’embedding può poi essere indicizzato su un DB vettoriale, per permettere una ricerca a bassa latenza, vincolo critico per alcune tipologie di applicazioni su larga scala [4]. Le scelte tecnologiche per implementare le features richieste dipendono, infine, da vari fattori, tra i quali: costi di licenza per l’uso di uno o più prodotti vendor, opportunità di soluzioni più vicine al “chiavi in mano”, o la possibilità di combinare tra loro capabilities fornite da strumenti open source, in base al grado di maturità e skills del team di sviluppo IT. Un framework di sviluppo open source con un buon grado di completezza è, ad esempio, Langchain. Con esso è possibile sviluppare applicazioni basate su LLM in maniera “vendor-agnostic”, scegliendo la tecnologia più adatta. Langchain fornisce strumenti per la creazione del contesto, per l’interfacciamento con basi di dati documentali, la possibilità di utilizzare i vari modelli forniti dai principali attori di mercato. La caratteristica principale è la possibilità di creare “chain”, cioè catene applicative combinando vari moduli per costruire la soluzione più adatta al proprio requisito.