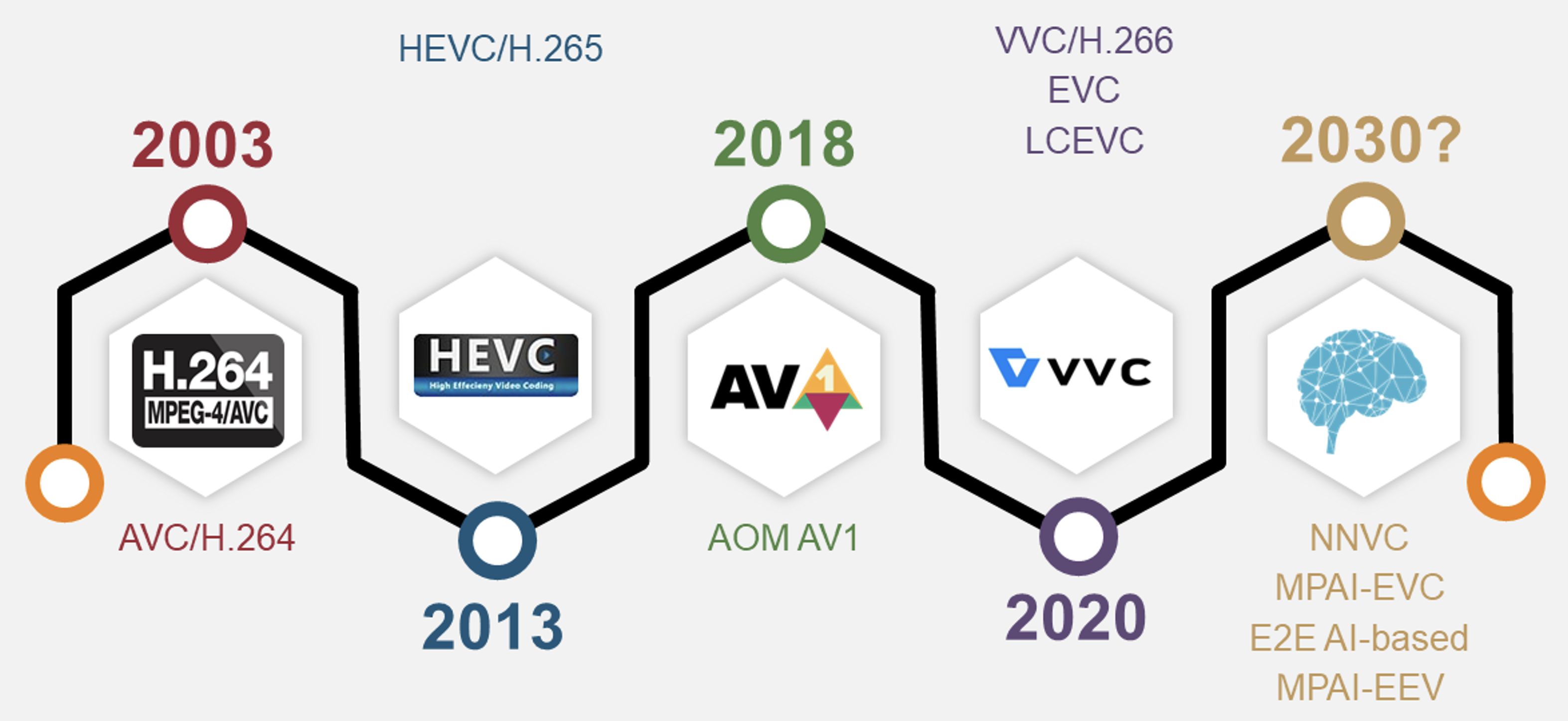
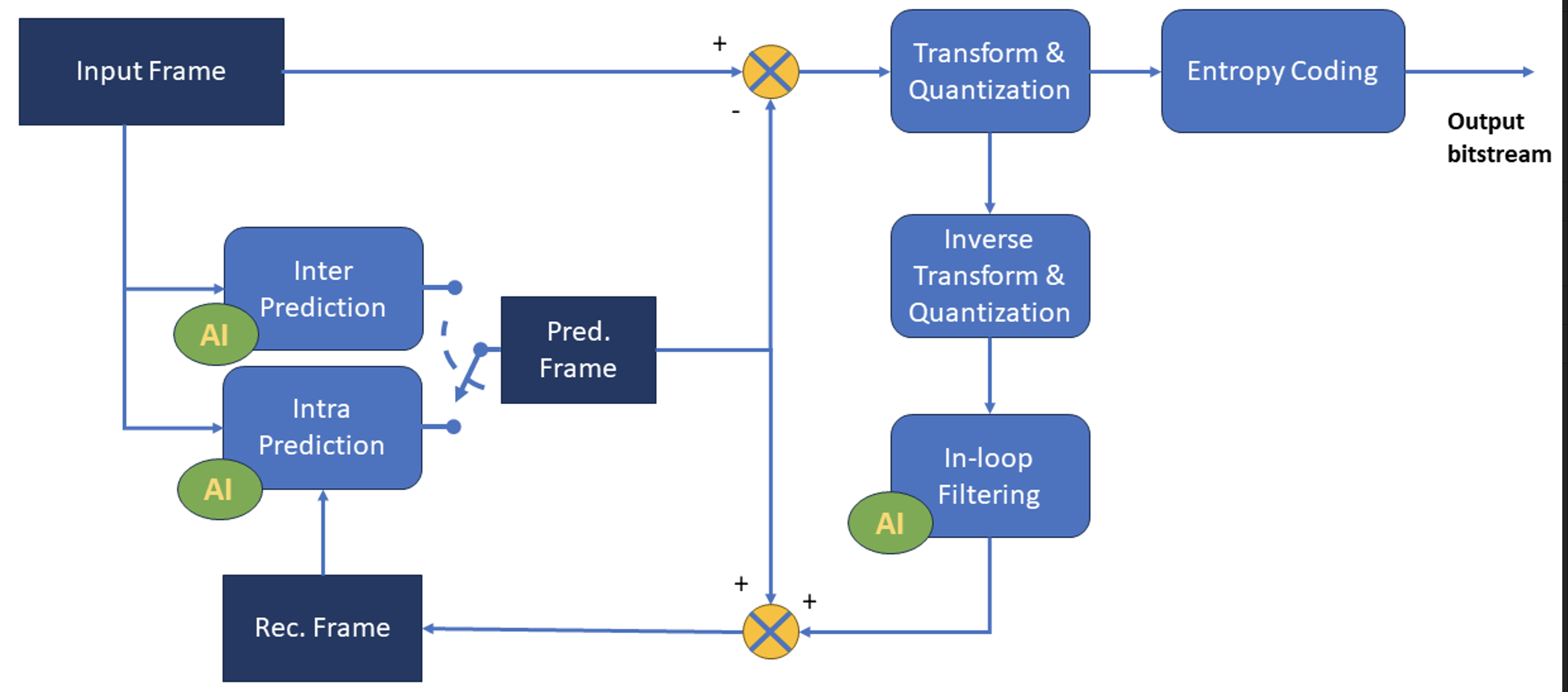
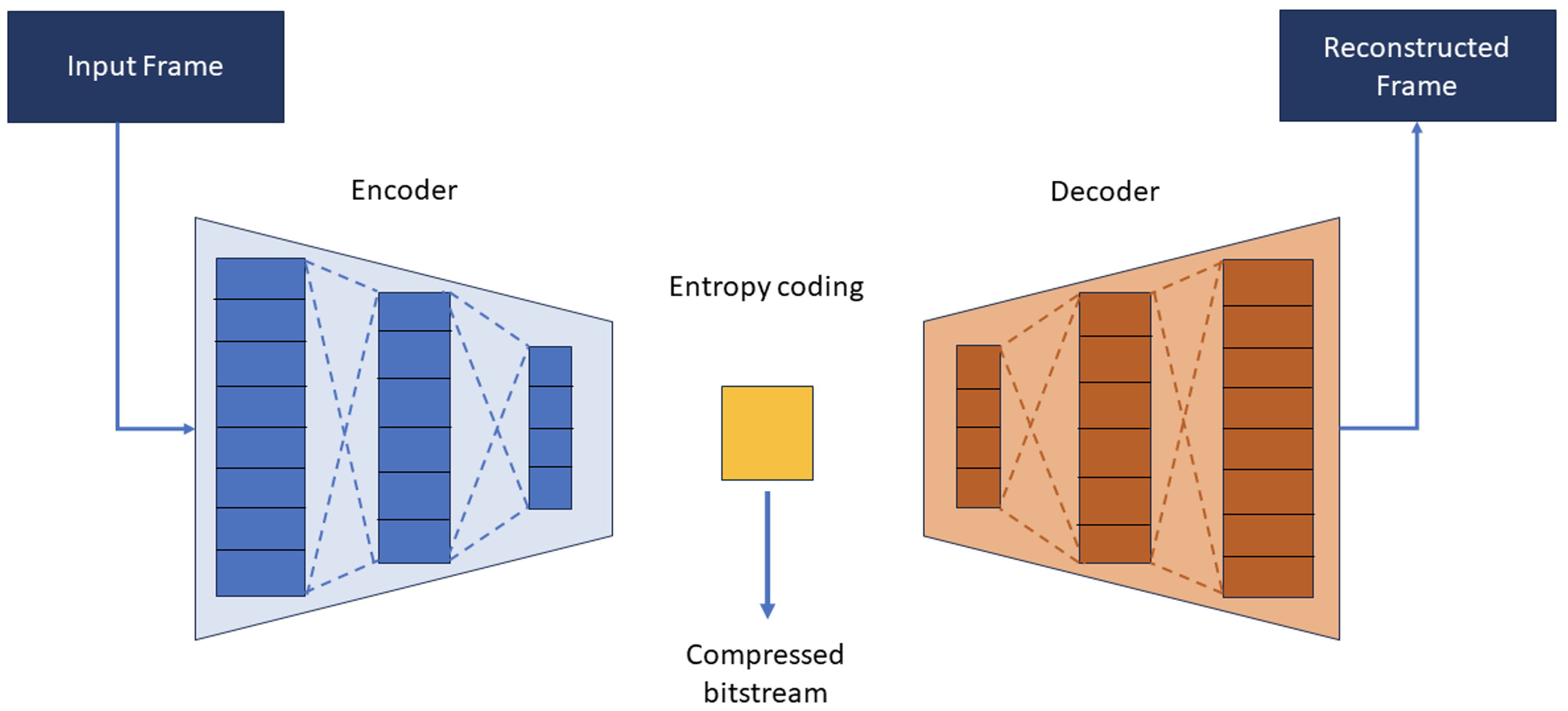
L’Intelligenza Artificiale è entrata a pieno titolo tra l’insieme di tecnologie impiegate stabilmente dai Media. Tecniche di Machine Learning sono in grado di comprendere, classificare, manipolare, ottimizzare formati e modalità di distribuzione e raccomandare contenuti sulla base delle abitudini e preferenze di fruizione degli utenti. L’Intelligenza Artificiale generativa può creare immagini, video, audio e testi, supportando i processi di creazione artistica, di produzione e post-produzione. La Comunità Scientifica negli ultimi anni ha sviluppato nuove tecniche basate sulle reti neurali profonde che possono essere applicate alla compressione dei video. Gruppi di lavoro internazionali, come ISO/IEC JTC1 SC29 WG5 (MPEG)/ITU-T SG16 Joint Video Experts Team (JVET) e Moving Picture, Audio and Data Coding by Artificial Intelligence (MPAI), hanno avviato attività esplorative che dovrebbero portare alla definizione di una nuova generazione di compressori video (codec) basati su IA nel corso di questo decennio, con benefici in termini di risparmio di banda e flessibilità di utilizzo rispetto alle soluzioni oggi disponibili. Queste nuove tecnologie potrebbero rivoluzionare servizi come streaming di video e gaming, videoconferenza, realtà virtuale e aumentata, e public safety.