

Verso una Greener AI
Scarica il PDF

Verso una Greener AI
1070 KB

I sistemi di Intelligenza Artificiale (AI) sono estremamente “energivori”, cioè consumano grandi quantità di energia sia nella fase in cui sono sviluppati sia nel loro utilizzo, perché usano grandi quantità di server e sistemi. Questo li rende differenti dalla maggioranza dei sistemi IT classici. Ci sono molti esempi che si possono fare a questo riguardo anche con notizie curiose e paradossali: per esempio, uno studio di qualche tempo fa dell’Università della California1, Riverside, e dell’Università del Texas, Arlington, ripreso anche dalla stampa generalista, avvisava che ChatGPT utilizza l’equivalente di una bottiglietta di acqua di mezzo litro2 per il raffreddamento dei server ogni 20-50 domande a cui risponde. Secondo Gartner3, p.es. “l’Intelligenza Artificiale consumerà più energia della forza lavoro umana” entro il 2025, a meno che non vengano compiuti passi significativi in termini di efficienza.” Un altro studio recente stima che Google, se passasse tutti i suoi sistemi di ricerca su AI, consumerebbe e più energia elettrica dell’Irlanda4. Google attualmente consuma oltre 18 TWh di elettricità all’anno, quasi 10 volte l’energia necessaria a un operatore di rete come TIM. Uno studio di SemiAnalysis5 rivela che ChatGPT si basa su un numero impressionante di quasi 29.000 GPU NVIDIA per fornire risposte e ha un costo operativo giornaliero superiore a 694.000 dollari. Ed ancora Microsoft6 sta assumendo esperti in costruzione di centrali nucleari!! Si ipotizza voglia costruirne una privata per alimentare alcuni dei propri data center.
Secondo uno studio della International Energy Agency7 pubblicato nel 2022 sulla rivista Nature Sustainability, si prevede che il consumo di energia per la formazione e l’implementazione dell’IA aumenterà da 10 a 50 volte entro il 2030. Ciò è dovuto a una serie di fattori, tra cui:
Lo studio ha inoltre rilevato che il consumo energetico dell’AI è concentrato in un numero limitato di paesi, tra cui Stati Uniti, Cina ed Europa. Questi paesi ospitano i più grandi data center cloud e aziende di Intelligenza Artificiale.
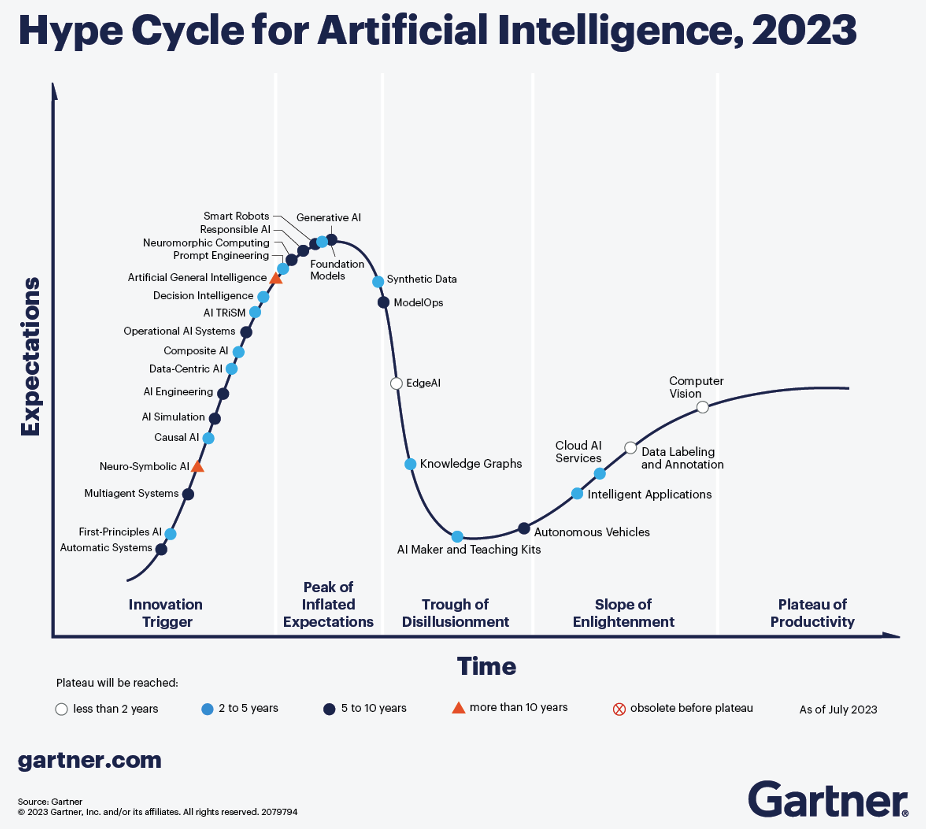
Figura 1: Hype Cycle Garner AI, 2023 (fonte: Gartner)
Siamo infatti al picco dell’Hype relativamente AI Generativa8 estremamente energivoro. Una delle caratteristiche dei nuovi sistemi AI è che mentre in passato, diversi scenari applicativi richiedevano lo sviluppo di modelli diversi, gli attuali modelli, di grandi dimensioni, assorbendo enormi quantità di conoscenza, possono adattarsi a molteplici scenari di business, abbassando significativamente la soglia per lo sviluppo e l’applicazione dell’IA ed accorciando il ciclo dalla tecnologia all’applicazione”. Ad esempio, uno studio ha scoperto che l’addestramento di un grande modello linguistico chiamato GPT-3 ha richiesto 626.000 tonnellate di emissioni di CO2, che equivalgono alle emissioni annuali di 500 auto americane9. La Fig.2 indica il paradosso di questa crescita, insostenibile.
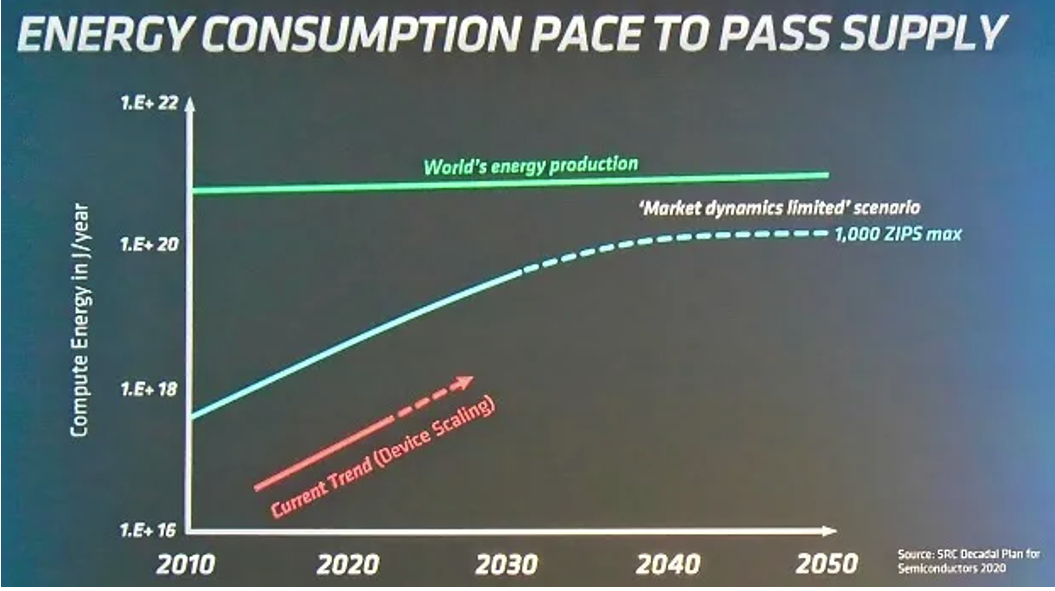
Figura 2: Energy sistemi di AI se la crescita fosse non controllata – (fonte : AMD10)
Come misura dello sviluppo impetuoso dell’AI, possiamo guardare agli investimenti degli ultimi anni: ebbene gli investimenti di Venture Capital nelle società di Intelligenza Artificiale hanno subito un’accelerazione negli ultimi dieci anni. Secondo i dati Crunchbase11, tra gennaio 2013 e il terzo trimestre del 2023 sono stati investiti più di 300 miliardi di dollari in finanziamenti di venture capital in oltre 16.000 aziende del settore. A partire dal terzo trimestre del 2023, circa 1 su 4 dollari di rischio negli Stati Uniti quest’anno è andato a una startup che incorpora l’Intelligenza Artificiale nella sua attività. A partire dalla fine del 2022 con l’apertura al grande pubblico di ChatGPT, l’attenzione ai sistemi di Intelligenza Artificiale (AI) si è particolarmente rivolta ai sistemi di cosiddetta Generative AI. Questi sistemi in grado di “generare” risposte verosimili a domande poste in linguaggio naturale, tradurre testi, generare immagini, musica, video o altri dati “artificiali” con un minimo intervento umano, tipicamente partendo da input fatti di descrizioni testuali in linguaggio naturale. Con innumerevoli campi di applicazione, le tecnologie di Generative AI usano modelli di “Machine Learning” per trovare correlazioni statistiche tra dati di addestramento (training data) e gli output che sono in grado di generare. Questo perché molte applicazioni di Intelligenza Artificiale generativa sono costruite su modelli di base chiamati “foundation models”. Si tratta di algoritmi di apprendimento automatico che sono stati pre-addestrati su enormi set di dati e che sono adattabili a dati “adiacenti”. In linea di massima, la fase di addestramento di questi modelli è molto onerosa se pensiamo alle risorse di calcolo di cui ha bisogno, ma non è estremamente complessa algoritmicamente. Anche la fase di “generazione” è molto esigente come risorse di calcolo. Un modello generativo usato come chatbot o motore di ricerca è per esempio molto più impegnativo come risorse informatiche rispetto ad una query in un motore di ricerca tra documenti preesistenti come Google. Secondo un rapporto del 2022 dell’Agenzia internazionale per l’energia, l’AI è attualmente responsabile di circa l’1% del consumo globale di elettricità12. Tuttavia, il rapporto prevede anche che il consumo di elettricità dell’IA potrebbe aumentare fino a 50-100 volte entro il 2030.
Un’azienda specializzata, SemiAnalysys13, ha provato a stimare cosa succederebbe al conto economico di Google se il modello ChatGPT venisse intromesso nelle attività di ricerca esistenti di Google. Ne risulta che l’impatto sarebbe devastante. Ci sarebbe una riduzione di 36 miliardi di dollari nel reddito operativo, dovuti ai costi di inferenza di sistemi basati su Large Language Model (LLM) come appunto Google Bard o OpenAi ChatGPT. Secondo lo studio, l’implementazione dell’attuale ChatGPT in ogni ricerca effettuata da Google richiederebbe circa mezzo milione di server con un totale di oltre 4 milioni di GPU A100. Il costo totale di questi server e reti supera i 100 miliardi di dollari solo in Capex.
Sono dunque necessarie strategie e azioni per ridurre l’impatto ambientale dei prossimi sistemi AI. Le azioni che si stanno intraprendendo sono su tre linee di lavoro:
Nel resto dell’articolo sintetizzeremo alcune di queste opportunità, in particolare l’evoluzione di alcuni chip specializzati e lo sviluppo di nuovi modelli AI meno energivori.
Come illustra la Fig.314, il numero di parametri (di conseguenza la larghezza e la profondità) delle reti neurali e quindi la dimensione del modello sta aumentando. Per creare modelli di deep learning migliori e potenziare le applicazioni di Intelligenza Artificiale generativa, le organizzazioni necessitano di maggiore potenza di calcolo e larghezza di banda di memoria.
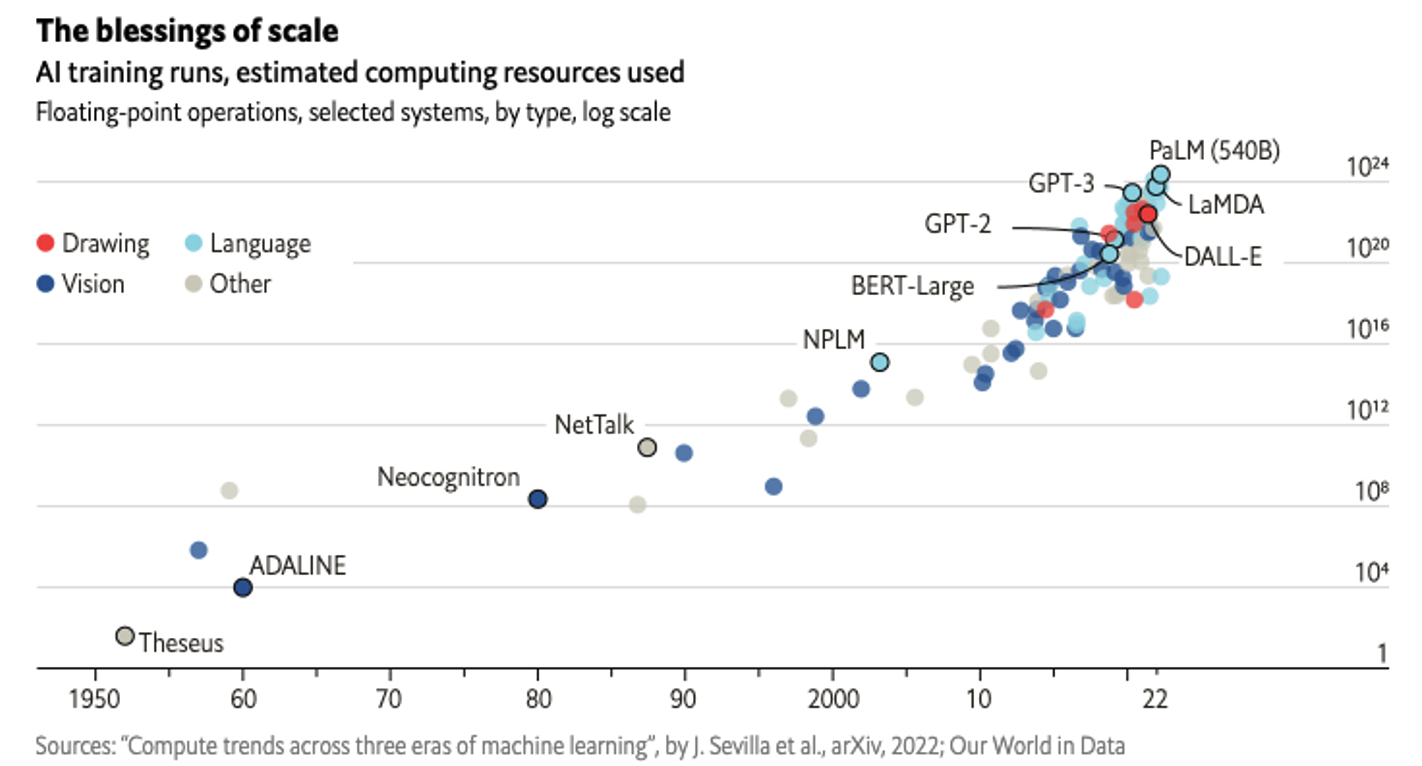
Figura 3: Crescita esponenziale della complessità dei modelli di training AI
Anche la Fig.4 mostra come i chip generici (come le CPU) non possono supportare modelli di deep learning altamente parallelizzati. Pertanto, i chip AI che consentono capacità di elaborazione parallela sono sempre più necessari. Questo processo migliora anche l’efficienza energetica.
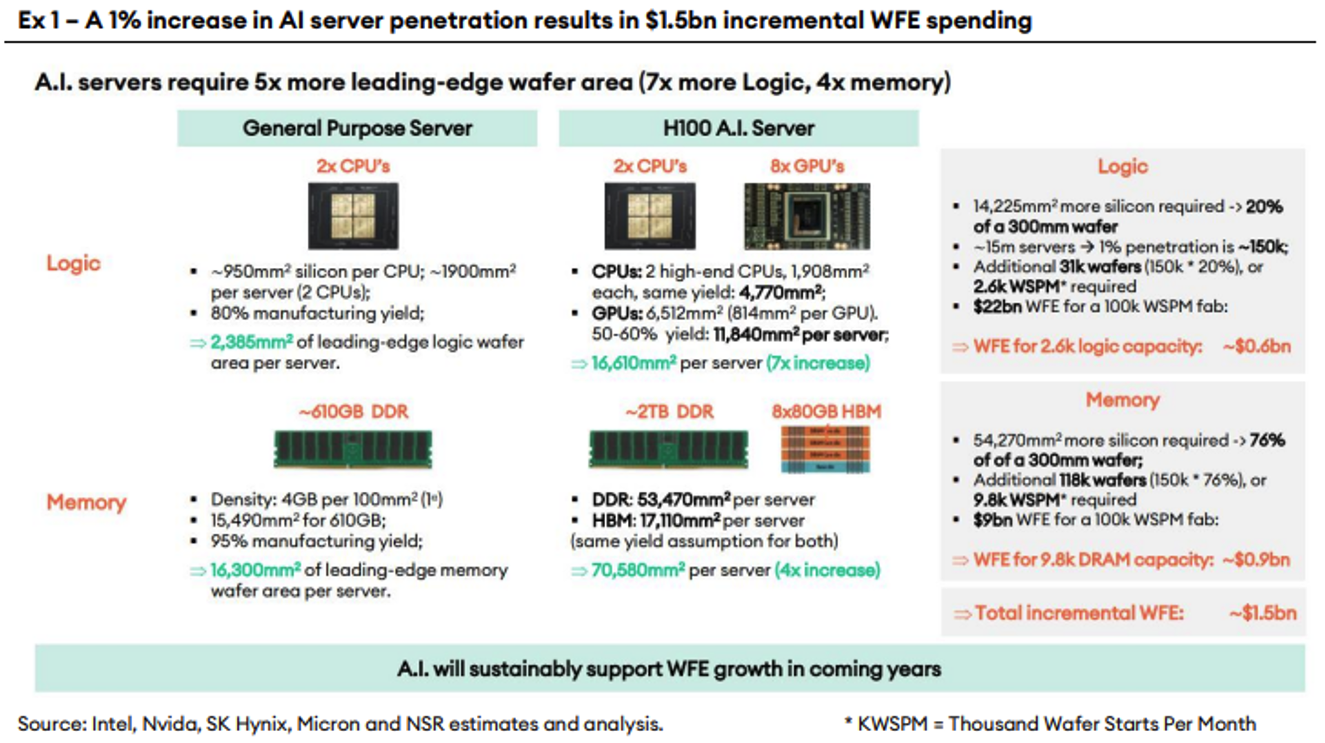
Figura 4: Impatto della diffusione dell’AI nella industria dei Chip secondo NSR15
Nuove CPU e microchip possono contribuire a rendere l’AI generativa più efficiente dal punto di vista energetico. L’hardware più recente è in genere più efficiente dell’hardware precedente, il che significa che può eseguire le stesse attività consumando meno energia. Oltre alle nuove CPU e microchip, ci sono una serie di altre innovazioni hardware che potrebbero contribuire a rendere l’AI generativa più efficiente dal punto di vista energetico. Ad esempio, i ricercatori stanno sviluppando nuovi tipi di memoria che sono più efficienti dal punto di vista energetico rispetto alla DRAM tradizionale. Di seguito elenchiamo alcuni di questi progressi.
Nvidia H100 e A100: i principali chip per AI
Nvidia è un leader mondiale nella produzione di chip per l’Intelligenza Artif iciale (AI), le sue “GPU” sono considerate il benchmark in molti con testi. I suoi chip sono utilizzati in una vasta gamma di applicazioni, tra cui la visione artificiale, il riconoscimento del linguaggio naturale e l’apprendimento automatico. I principali chip Nvidia per AI sono l’H100 e l’A100.
Un tema di sicurezza nazionale
I chip Nvidia sono così potenti che la loro esportazione dagli USA è soggetta a restrizioni. In particolare, il 23 ottobre 2023, il Dipartimento del Commercio degli Stati Uniti ha imposto nuove restrizioni all’esportazione di chip e tecnologie avanzate verso la Cina. Queste restrizioni includono l’H100 e l’A100 di Nvidia, che sono i chip AI più avanzati dell’azienda. Le nuove restrizioni impongono a Nvidia di richiedere una licenza al Dipartimento del Commercio per esportare i chip H100 e A100 in Cina. Il Dipartimento del Commercio esaminerà ogni richiesta di licenza caso per caso e può negare la licenza se ritiene che l’esportazione del chip possa rappresentare una minaccia per la sicurezza nazionale degli Stati Uniti.
Intel
Intel è il più importante player nel mercato dei chip AI. L’azienda offre una varietà di chip AI, sia per l’uso nei data center che nei dispositivi mobili. I principali chip Intel per AI sono i seguenti: Gaudi2 e Ponte Vecchio.
Ponte Vecchio ha una potenza di calcolo FP32 di 52 teraFLOPS, mentre l’H100 ha una potenza di calcolo FP32 di 60 teraFLOPS. Ciò significa che l’H100 ha una potenza di calcolo FP32 del 16% superiore a quella del Ponte Vecchio. Il seguente grafico confronta il consumo energetico del Ponte Vecchio con quello di alcuni altri chip AI di fascia alta:
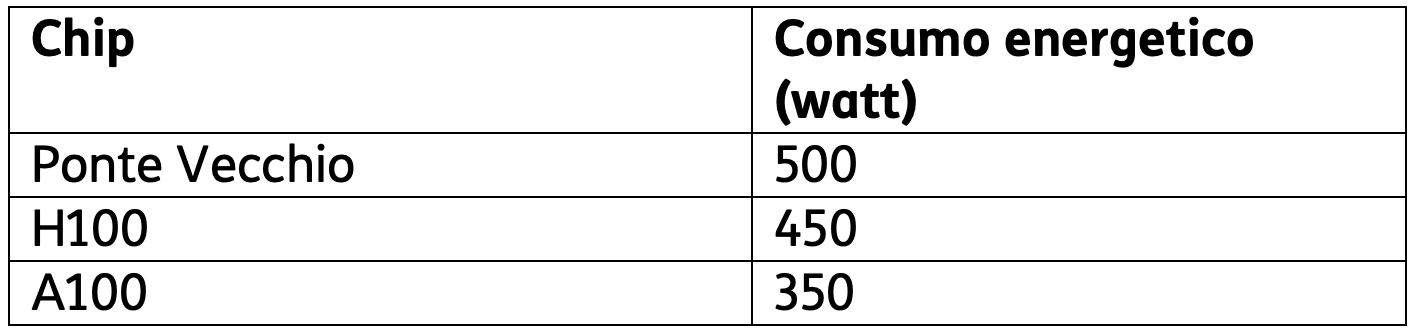
Tabella 1
Come si può vedere dalla tabella, il Ponte Vecchio ha un consumo energetico superiore a quello di altri chip AI di fascia alta. Ciò è dovuto alla sua maggiore potenza di calcolo.
Qualcomm
Qualcomm, un altro gigante dei semiconduttori, dispone di chip proprietari per AI per data center. I primi chip AI di Qualcomm, datati 2022, sono denominati Cloud AI 100. Qualcomm ha annunciato che avrebbe lanciato un secondo chip AI per data center, chiamato Cloud AI 200 ed un altro per il 2024, chiamato Cloud AI 300, con prestazioni maggiori. Qualcomm ha dichiarato che il Cloud AI 200 ha un consumo energetico di 300 watt per chip. Questo consumo energetico è inferiore rispetto a quello di altri chip AI per data center, come le GPU di Nvidia.
E’ interessante notate che i principali attori cloud sviluppino chip “in house” oltre che utilizzare chip dei principali produttori di semiconduttori come ARM, Nvidia e In tel e altri. Microsoft ha presentato nel novembre 2023 i suoi nuovi chip per l’Intelligenza Artificiale, denominati Maia 100. Questi chip sono progettati per migliorare le prestazioni e l’efficienza energetica dei carichi di lavoro AI, come il machine learning e il deep learning. Microsoft ha affermato che i chip Maia saranno utilizzati nei suoi data center per migliorare le prestazioni di una serie di servizi cloud, tra cui Azure Machine Learning, Azure Cognitive Services e Azure Bot Service. Come molti altri, questi chip utilizzano per efficienza energetica un sistema di raffreddamento liquido, che aiuta a mantenere il chip a una temperatura operativa ottimale.
Google
Google ha sviluppato una serie di chip proprietari per cloud e AI, tra cui: Tensor Processing Unit (TPU); Edge TPU e Bard; anch’essi utilizzano un sistema di raffreddamento liquido. In particolare, Google ha annunciato il lancio di una nuova generazione di TPU, denominata TPUv5. Le TPUv5 offrono prestazioni ed efficienza energetica significativamente superiori rispetto alle generazioni precedenti. Google prevede di utilizzare le TPUv5 nei suoi data center per alimentare applicazioni AI sempre più complesse.
Amazon
Amazon ha due chip proprietari per l’Intelligenza Artificiale nel cloud: Trainium ed Inferentia. Amazon ha iniziato a utilizzare questi chip nei suoi servizi cloud nel 2022. I chip Trainium vengono utilizzati per alimentare applicazioni basate sull’Intelligenza Artificiale, come il riconoscimento vocale e la visione artificiale. I chip Inferentia vengono utilizzati per alimentare applicazioni basate sull’Intelligenza Artificiale, come la traduzione automatica e il riconoscimento delle immagini. Amazon prevede di rendere questi chip disponibili anche ai clienti terzi in futuro. Secondo Amazon, il chip Trainium offre un’efficienza energetica fino a 10 volte superiore rispetto a una GPU tradizionale per l’addestramento dei modelli di AI. Questo significa che il chip Trainium può eseguire lo stesso lavoro con un consumo energetico inferiore, il che può portare a risparmi significativi sui costi operativi. Il chip Inferentia offre un’efficienza energetica fino a 4 volte superiore rispetto a una GPU tradizionale per l’inferenza dei modelli di AI. Questo significa che il chip Inferentia può eseguire lo stesso lavoro con un consumo energetico inferiore, il che può portare a miglioramenti delle prestazioni e dell’economicità delle applicazioni AI. Ad esempio, Amazon afferma che il chip Trainium può ridurre il consumo energetico del 70% per l’addestramento di un modello di Intelligenza Artificiale per la visione artificiale. Questo può comportare un risparmio fino a 1 milione di dollari all’anno per un’azienda che utilizza il chip per addestrare i propri modelli AI.
Meta
A dicembre 2023, Meta non dispone ancora di chip proprietari per AI. Tuttavia, l’azienda ha annunciato di essere al lavoro sullo sviluppo del suo primo chip proprietario, chiamato MTIA (Meta Training and Inference Accelerator), che dovrebbe essere disponibile nel 2025. In attesa dell’uscita del MTIA, Meta utilizza chip di terze parti, come le GPU di Nvidia e le CPU di In tel. L’azienda ha anche sviluppato un supercomputer da 16.000 GPU, chiamato Research SuperCluster (RSC), che viene utilizzato per addestrare modelli di Intelligenza Artificiale di grandi dimensioni.
AMD
AMD, anch’esso un gigante dei chip, ha annunciato il 7 dicembre 2023 i nuovi chip Instinc t MI300X per l’Intelligenza Artificiale. Questi chip offrono prestazioni ed efficienza energetica notevolmente migliorate rispetto ai modelli precedenti. La caratteristica più importante dei nuovi chip MI300X è la presenza di 192 gigaby te di memoria nella HBM316. Questa memoria ultraveloce è in grado di gestire grosse moli di dati in trasferimento, rendendo i chip MI300X particolarmente adatti per i modelli AI più grandi. I nuovi chip MI300X sono in grado di eseguire l’inferenza AI a una velocità di 300 teraflops, il che li rende circa il 30% più veloci rispetto ai modelli precedenti. Inoltre, i chip MI300X consumano circa il 20% di energia in meno rispetto ai modelli precedenti, rendendoli più efficienti dal punto di vista energetico. AMD ha già annunciato che i chip MI300X saranno utilizzati da Meta e Microsoft per i loro prodotti e servizi basati sull’Intelligenza Artificiale.
Cenni a nuove architetture di chip per AI orientate al risparmio energetico
D-Matrix Corsair: la scommessa del “in memory computing”
D-Matrix è una startup inglese attiva nel campo dei chip “analogici” per AI. Sebbene le GPU siano incredibilmente potenti per i giochi o il mining di criptovalute, le loro prestazioni non sono ottimali per l’esecuzione di un’Intelligenza Artificiale generativa.
L’azienda dichiara17:
Mythic
Un’altra startup, Mythic18 sfrutta la bassa latenza e il basso consumo energetico del calcolo analogico. Mythic afferma di aver creato una soluzione unica e rivoluzionaria che promette di affrontare i limiti del digitale fornendo allo stesso tempo specifiche migliorate rispetto alle migliori soluzioni digitali della categoria: un motore di calcolo analogico (ACE).
Expedera
Expedera19 è un’altra azienda di semiconduttori con sede in California. L’azienda ha collaborato con importanti aziende tecnologiche, tra cui Google, Microsoft e Amazon ed ha recentemente aperto un cen tro di R&D in UK.
Nel complesso, il nuovo hardware ha il potenziale per svolgere un ruolo significativo nel rendere l’AI generativa più efficiente dal punto di vista energetico. Tuttavia, è importante notare che l’hardware non è l’unico fattore che influisce sul consumo energetico. Anche il software utilizzato per addestrare e distribuire modelli di Intelligenza Artificiale generativa svolge un ruolo. Ecco alcuni miglioramenti del software20 che possono aiutare a ridurre l’impatto energetico dell’addestramento e dell’utilizzo dell’IA:
Esistono poi diversi studi su modelli LLM pensati per essere efficienti dal punto di vista energetico.
Questi studi si concentrano su una serie di tecniche, tra cui:
Riportiamo a titolo di esempio studi su modelli LLM efficienti dal punto di vista energetico21:
Questi studi stanno dimostrando che è possibile sviluppare modelli LLM efficienti dal punto di vista energetico senza sacrificare troppo le prestazioni. Questo è importante per ridurre l’impatto ambientale dell’Intelligenza Artificiale.
L’effetto Jevons22 si basa sull’idea che un aumento dell’efficienza nell’uso di una risorsa può portare a un aumento assoluto dell’uso di quella risorsa anziché a una diminuzione.
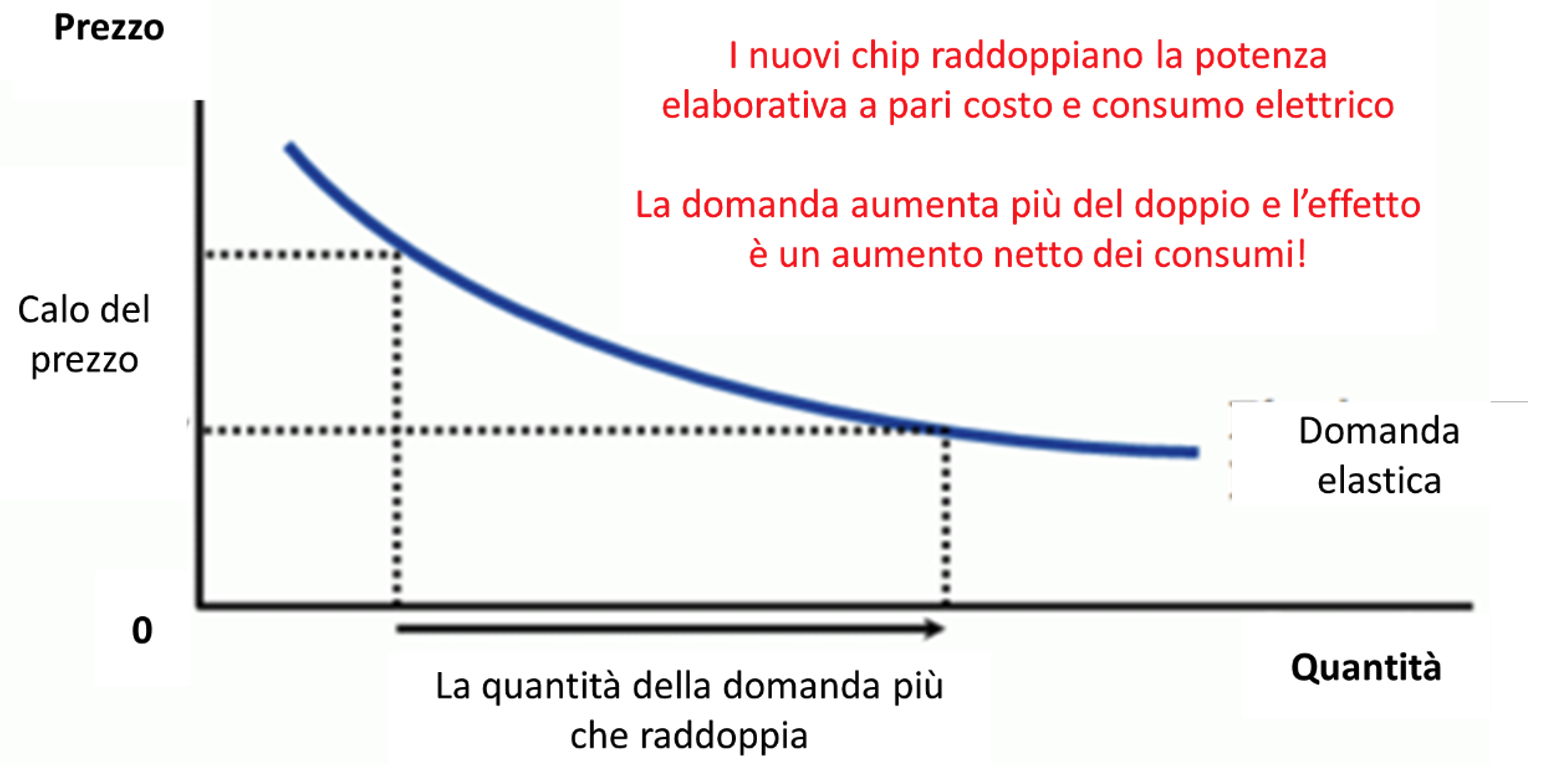
Figura 5: Curva domanda secondo l’effetto Jevons23
Ad esempio, se si sviluppa una tecnologia più efficiente dal punto di vista energetico per un certo processo industriale, potrebbe diventare più conveniente utilizzare quella tecnologia, spingendo le imprese ad espandere la produzione o ad utilizzare tale processo più frequentemente. Questo aumento dell’efficienza potrebbe portare a un aumento netto del consumo totale di energia, anziché ad una diminuzione, proprio perché l’efficienza rende più conveniente utilizzare quella risorsa. Per evitare questa trappola occorre adottare specifiche politiche che incentivino un uso più responsabile delle risorse. L’AI sta vivendo con lo sviluppo dei sistemi generativi basati su LLM un’ulteriore accelerazione. Tuttavia, lo sviluppo e l’utilizzo di soluzioni AI, unito al gran numero di progetti in partenza, ha un impatto energetico importante. Le tecniche per ridurre questo impatto richiedono chip sempre più specializzati, i cui costi di R&D e di produzione sono enormi, ed un utilizzo più ottimale dei modelli attraverso soluzioni software. Entrambe le strade saranno necessariamente perseguite nei prossimi anni.