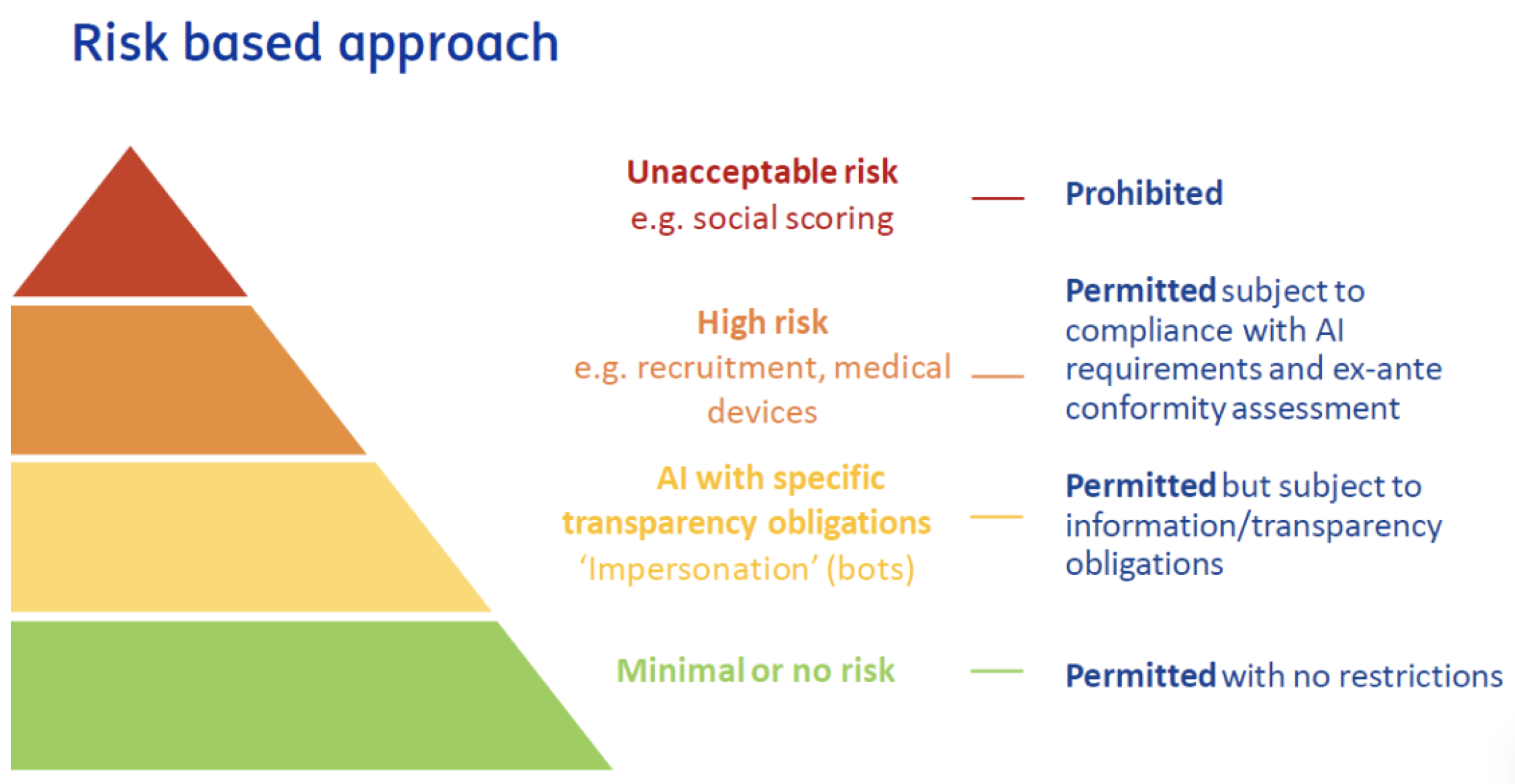
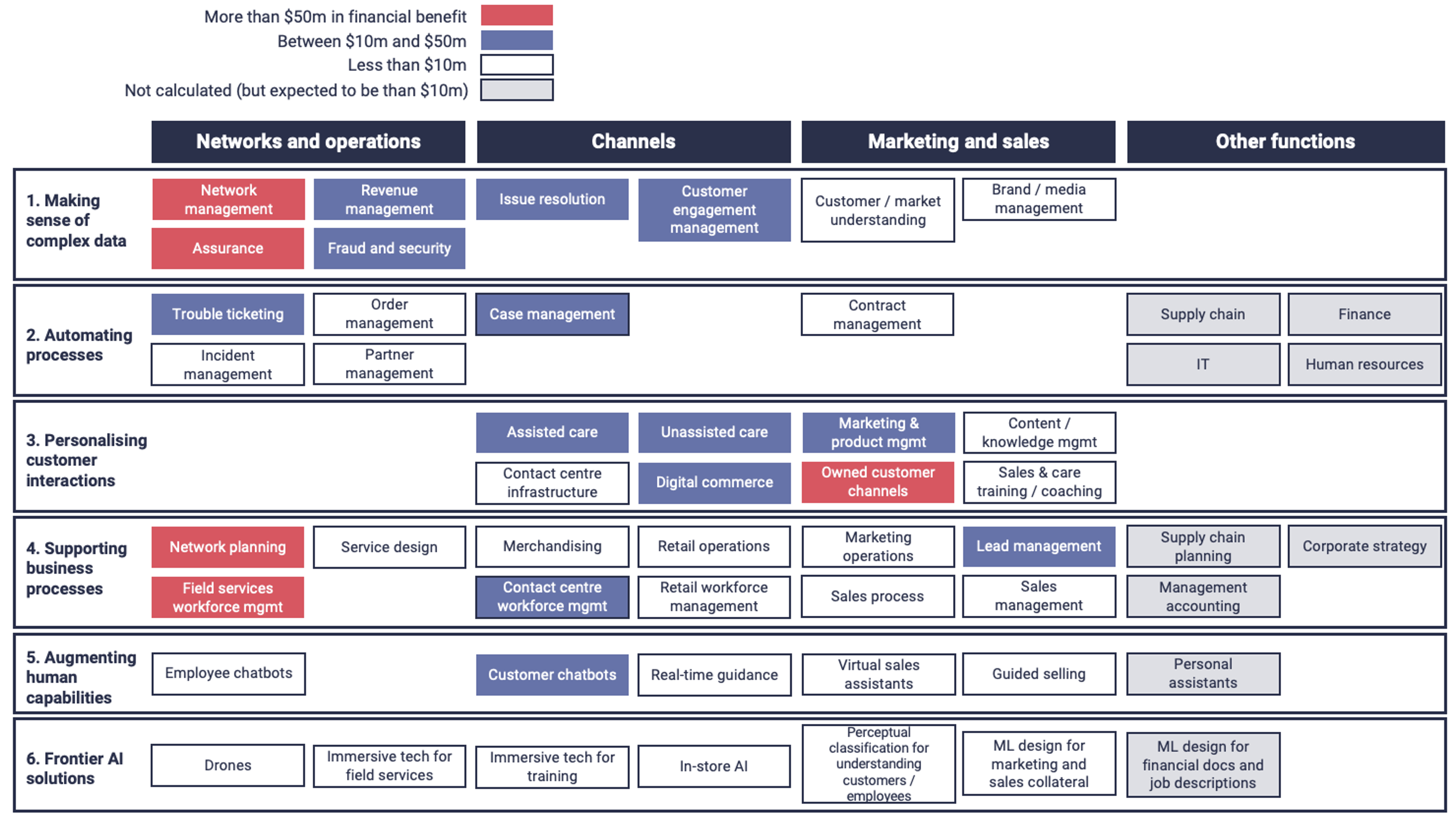
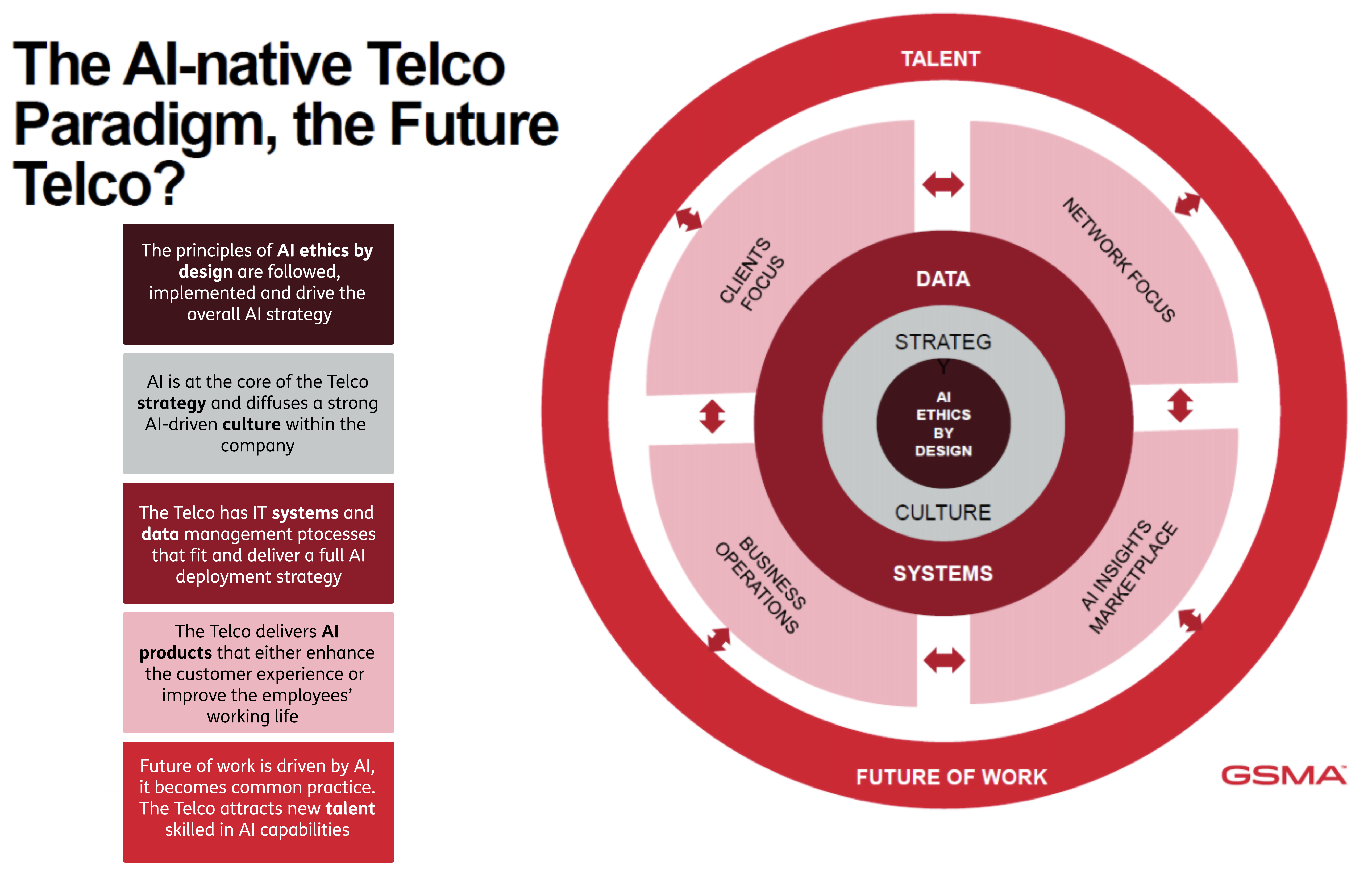
Al centro del paradigma AI native telco la GSMA mette l’AI Ethics by design, ovvero l’incorporazione di regole etiche nell’uso dell’AI come peraltro già recepito da diversi codici etici delle aziende partecipanti al progetto. A partire da principi etici, l’AI dovrà diventare parte integrante della cultura aziendale e quindi influenzarne le strategie di business. Ma per poter mettere a terra il concetto di AI native telco, gli operatori dovranno investire maggiormente nelle loro data foundations ovvero il loro impianto di dati che saranno il materiale grezzo su cui innestare gli algoritmi AI. I dati per l’addestramento dei sistemi AI dovranno essere di alta qualità, diversificati e rilevanti oltre ad avere una governance che assicuri privacy, trasparenza ed accountability dei sistemi AI tali da poter capire e spiegare il loro funzionamento e quindi eliminare effetti indesiderati quali il bias1. Un data foundation consistente si ottiene in base ad un insieme di processi comunemente definiti – data collection, data cleaning, data integration, data annotation, data governance, storage & management. Molti di questi processi sono gestiti ancora in maniera manuale e quindi dovranno essere oggetto di automazione da parte dei telco al f ine di rendere l’enorme mole di dati prodotti dalle reti e dai sistemi di CRM actionable per i sistemi AI. Il progetto mette anche in evidenza il problema dei silos tra dati di rete e di CRM e quindi la necessità di maggior collaborazione tra i teams aziendali che li gestiscono. I dati per addestrare sistemi AI sono particolarmente critici dal punto di vista della privacy e quindi della protezione dei dati personali del cliente per la quale è prevista la compliance alle varie regolamentazioni locali e regionali. L’adempienza a principi di privacy sarà critica e potrà essere ottenuta grazie ad algoritmi di anonimizzazione. Il tradeoff tra rispetto della privacy e utilità dei dati è uno degli elementi di ricerca più importanti emersi nel progetto per avere in futuro sistemi AI human centric. La ricerca sarà focalizzata sull’uso di dati sintetici ovvero dati creati artificialmente (anche dai stessi sistemi AI) che simulano i dati reali. Gli ambiti di ricerca più rilevanti emersi su questo tema sono la rappresentatività, l’eliminazione di bias insiti nella loro generazione e quindi le tecniche di valutazione della loro bontà. Un numero crescente di operatori tra cui la stessa TIM ha in esercizio sistemi AI ma il campo di applicazione rimane ancora limitato ai casi di utilizzo previamente descritti. Per rendere pervasivo l’uso dell’AI in tutti gli ambiti di applicazione sarà necessario determinare azioni di scaling sull’AI. A tal fine il progetto ha individuato nella standardizzazione degli use case AI più comuni e nell’applicazione del concetto di DevOps all’AI (MLOps) le vie percorribili per scalare l’uso dell’AI in tutti gli ambiti aziendali di un telco. Il progetto indica nuove applicazioni dell’AI in ambito rete che hanno bisogno di ricerca. Ad esempio, nella gestione della 5G core e RAN si dovrà fare più ricerca sull’automazione di alcuni tasks che limitino l’intervento umano e quindi sulla pedictive maintenance basata su AI che possa ridurre sensibilmente i guasti e gli interventi di riparazione. Il progetto indica nella configurazione automatica di rete (Self Organizing Network) per limitare la necessità di configurazioni umane, nel traffic optimisation per l’overprovisioning di rete grazie all’allocazione di risorse di rete just in time i temi di ricerca prioritari. La network automation sarà complessivamente una area di ricerca sull’AI a se stante, in ottica zero touch management per ridurre al minimo l’intervento umano nella gestione delle rete ed ottimizzarne gli OPEX. Lo smart energy management è emerso come importante tema di approfondimento per l’AI che può diventare una arma per fare saving su una voce di OPEX sempre più critica per i telco. In questo contesto si dovrà approfondire l’uso dell’AI per predire i consumi energetici in base alle predizioni di traffico e quindi operare predittivamente sulla configurazione di rete. L’ottemperanza al quadro regolatorio fornisce ulteriori temi di ricerca. L’explicability dell’AI è un tema che molti operatori dovranno affrontare in particolare sui mercati europei. Uno dei temi più rilevanti sarà il passaggio dalla correlazione (relazioni tra variabili) alla causation (influenza causale tra variabili) nel machine learning, dovendo poter inferire sulla causalità tra variabili per aumentare l’explicability dei sistemi AI. Il progetto indica nella ricerca in campi quali controlled experiments (si cambia una variabile e si vede l’effetto su una altra), il time order (causalità temporale tra variabili), il mechanism explanation (trovare meccanismi plausibili di causalità tra variabili), la reverse causality (se c’è causalità inversa tra variabili) e l’additional data (aggiungere dati per individuare causalità) l’individuazione di possibili soluzioni. Molti dei temi di ricerca individuati si possono inquadrare come sviluppo di digital twins delle reti, con gli algoritmi AI applicati ad una copia digitale prima ancora che fisica della rete. Il digital twin di una rete potrà essere usata nei vari ambiti di applicazioni precedentemente esaminati, come network optimisation, predictive maintanance ed il network planning. Infine, sempre in ambito rete un tema di ricerca fortemente attenzionato dagli operatori è quello del Network as a Service (NaaS) in cui funzionalità di rete possono essere virtualizzate e accesse tramite APIs. Servizi di NaaS già in essere riguardano servizi molto utilizzati come VPN o SDN ma che potranno essere migliorati attraverso l’uso dell’AI. Ma la ricerca sullo sviluppo dell’AI per i telco non riguarderà solo la rete ma toccherà anche il marketing e le operations di business. In questo campo un tema di ricerca prioritario riguarderà il paradigma del real time AI ovvero l’applicazione dell’AI ai dati in tempo reale ovvero al tempo della produzione stessa dei dati, per poter intraprendere azioni tempestive come offerte in real time in base alle esigenze estemporanee del cliente. Il Machine Learning verrà esplorato nella dimensione dell’ottimizzazione dei processi di business – in questo contesto la ricerca riguarderà temi quali il model based optimisation in cui ad essere ottimizzato sarà un modello del sistema, l’heuristic optimisation per ottimizzare la ricerca operative nella soluzione di problemi, il reinforcement learning, il bayesian optimisation sino ad arrivare al multi objective optimisation in cui ad essere ottimizzati sono diversi obiettivi di business secondo un trade off tra gli stessi obiettivi. Nel campo del CRM si tenderà a migliorare in particolare le chatbots. Lo sviluppo dell’ AI riguarderà la proattività nell’interazione (per anticipare i needs del cliente) e la capacità di dialogo. Sul versante della proattività si tratterà di definire il giusto bilanciamento tra personalizzazione della relazione e spam, per poter fornire in anticipo al cliente le informazioni utili ma senza sovraccaricarlo di messaggi. Per quanto riguarda la capacità di dialogo invece la ricerca riguarderà soprattutto l’applicazione di modelli di Generative AI che possano andare oltre il modello FAQ ed instaurare un vero dialogo con il cliente in linguaggio naturale. L’applicazione di generative AI verrà valutata anche per fornire chatbots di tipo multilanguage per servire clienti nel segmento etnico o i clienti in roaming. Una nuova dimensione della ricerca sull’AI applicata al mondo telecomunicazioni riguarderà l’Ethical & Responsible Business nell’ambito della Corporate Social Responsability (CSR). L’AI può avere sia aspetti positivi, legati alle applicazioni di forte impatto sociale come la salute o l’ambiente, ma anche aspetti fortemente negativi come il rischio di perdita della privacy o la discriminazione dovuti al bias insiti in sistemi di ML. La GSMA ha prodotto a riguardo un AI Ethics Playbook2 come manale d’uso per i telco per un uso etico dell’AI ma anche un Self Assessment Questionnaire (SAQ) per una autovalutazione sulla compliance raggiunta sui temi etici. La ricerca riguarderà in particolare le modalità di valutazione del rischio associato a determinati caso d’uso coerentemente con i dettami dell’AI Act europeo. Un fattore di rischio severo è quello della violazione della privacy – la ricerca sarà orientata a sviluppare sistemi AI e di ML che minimizzano il rischio di violare la privacy quando i sistemi vengono allenati con i dati dei clienti. Altro fattore con forte impatto negativo per un operatore è quello del bias (polarizzazione) dei sistemi AI che può essere di diversi tipi: bias di rappresentazione (i dati con cui viene addestrata la macchina AI riguarda una popolazione diversa da quella su cui verrà applicato il sistema), bias di misura (quando i dati raccolti contengono insito già un bias), bias dell’algoritmo (quando l’algoritmo AI è progettato con un bias insito). La ricerca in questo campo riguarderà quindi l’eliminazione o la mitigazione di qualsiasi forma di polarizzazione dei sistemi AI basato su tre metodologie: il pre processing con il quale i dati di addestramento sono pre processati prima di essere usati per l’addestrato per eliminare in anticipo forme possibili di bias, in-processing in cui la depolarizzazione avviene introducendo funzioni di fairness constrain optimisation contestualmente all’addestramento ed infine il post processing in cui il bias viene corretto solo a posteriori e non durante l’addestramento della macchina. La explanability dei sistemi AI è un tema di ricerca trasversale e necessita di diversi approcci a seconda del tipo di sistema AI. I sistemi di tipo black box presentano alte prestazioni negli outputs a fronte di una bassa trasparenza sul modello di funzionamento, i sistemi white box presentano al contrario maggiori qualità di explanability a fronte di prestazioni in uscita minori. Esistono anche modelli AI intermedi di tipo grey box con diversi tradeoff tra prestazioni ed explanability. Metodologie come LIME o SHAP permettono un certo grado di interpretabilità di sistemi di tipo black box che sono quelli più critici. Infine, sarà necessaria molta ricerca sul tema della sostenibilità dell’AI considerando che ad oggi il consumo energetico dei grandi sistemi AI/ML comportano un consumo di energia proibitivo. Il tema di ricerca, il Green AI, è molto vasto ed esula dal campo della TLC. SI è valutato che l’addestramento di un modello GPT ha le stesse emissioni CO2 del ciclo di vita di 5 autovetture con motore termico. La ricerca riguarderà modelli di chipset dedicati a minor consumo ed algoritmi AI con minimo consumo energetico by design. Dall’altro lato l’AI può supportare la sostenibilità in altri settori – AI for Sustainibility – contribuendo in maniera positiva alla sostenibilità ambientale, sociale ed economica. Su questo tema sono attive iniziative come AI4I (AI for Impact) della GSMA o AI4Good (AI for Good) delle Nazioni Unite.