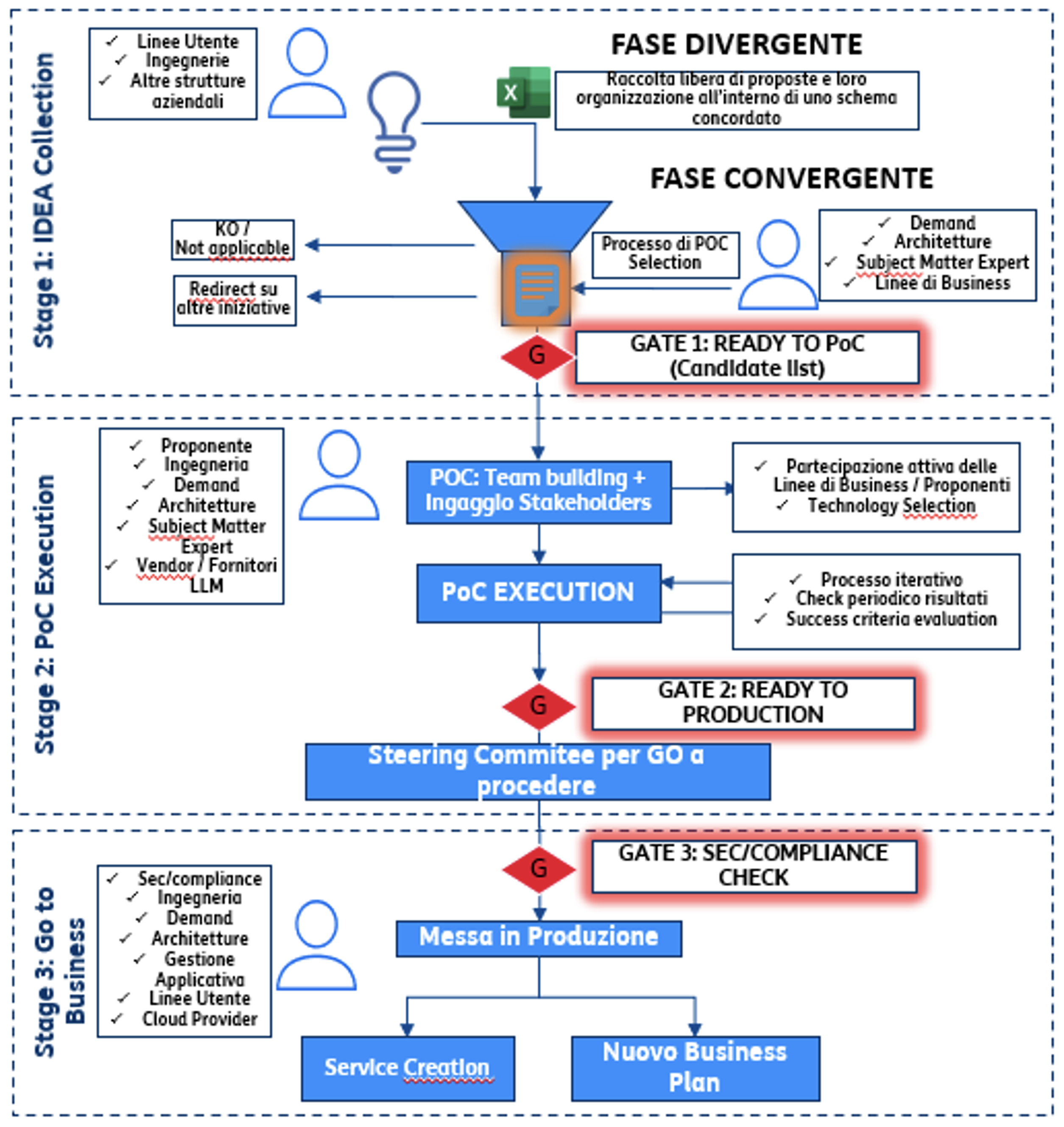
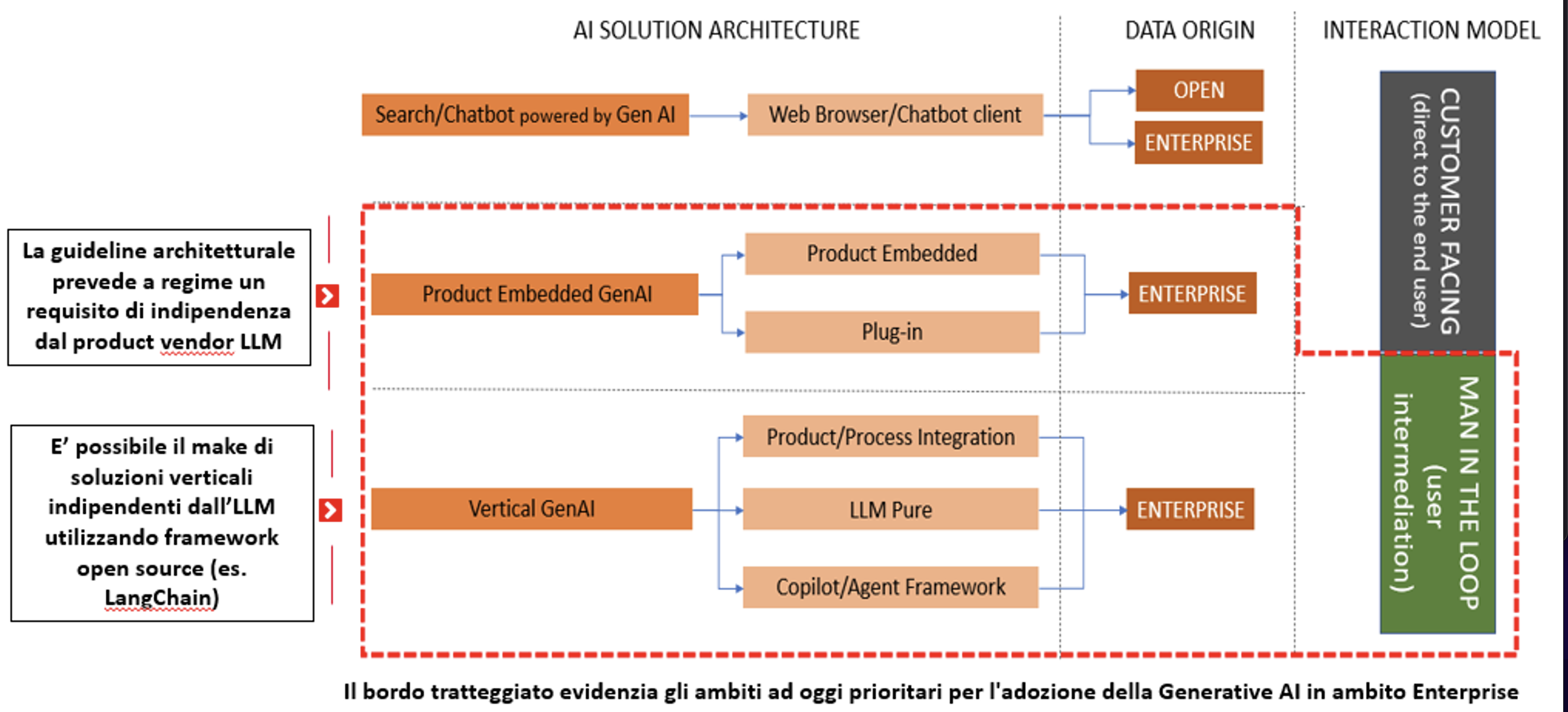
Le possibili applicazioni della GenAI coprono uno spettro molto ampio e la quasi totalità degli use case proposti dagli analisti si declinano contemporaneamente su più industry. A questi casi cross si aggiungono una serie di use case specifici del settore telco.
Opportunità strategiche
Case a maggior diffusione
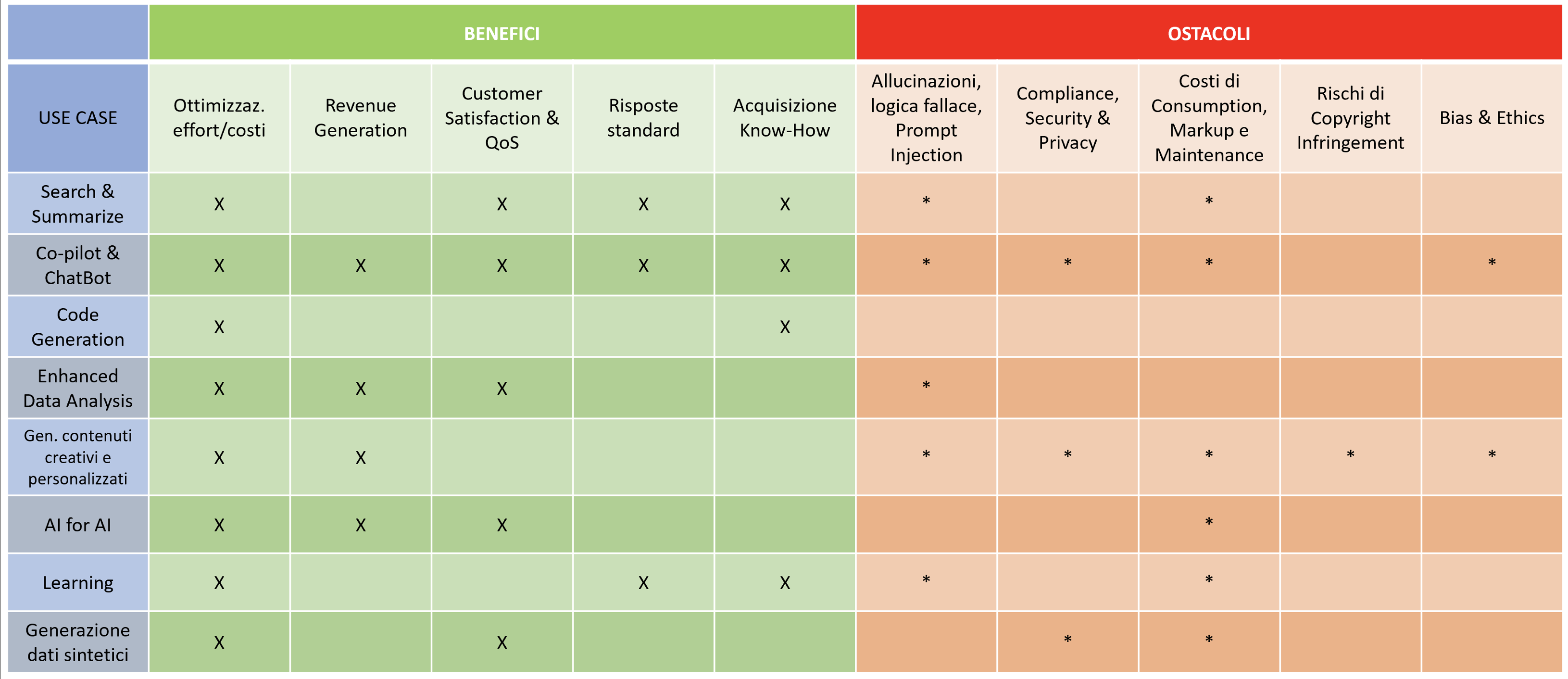
Conversational AI su KB – a.k.a. Search & Summarize
Si tratta dello use case di gran lunga più diffuso e prevede la creazione di un chatbot (o Conversational AI) in grado di dialogare con un esperto di dominio sul contenuto di un set di documenti di riferimento (manualistica, contratti, documentazione interna di Privacy & Compliance, etc.) [AWS]. L’esperto, a valle dell’“addestramento” iniziale del bot, può porgli delle domande e ottenere risposte. Le domande possono anche richiedere step di ragionamento da parte del bot, come l’aggregazione di informazioni o il confronto di punti di vista. Tecnicamente le soluzioni stanno ancora evolvendo, cercando di creare schemi di prompting capaci di “far ragionare” il LLM facendogli suddividere task ad oggi per lui troppo complessi in sotto-task più semplici. L’esecuzione di questi sottotask permette la raccolta delle informazioni necessarie per rispondere all’utente. Su questo fronte, è bene tener d’occhio anche le offerte evolutive delle applicazioni office: Microsoft Office 365 con Copilot, Google Duet AI, che promettono di abilitare capacità di interfacciamento conversazionale con i propri documenti.
Co-pilot per Customer Care, Vendite e attività di Operation dei tecnici; ChatBot
Questo case, che è una specializzazione del precedente, prevede la disponibilità per gli Operatori e per i tecnici di rete di interfacce conversazionali che li supportino da un lato nella risposta alle esigenze dei clienti [O2] [Acc] e dall’altro nel trovare soluzioni e guide durante fasi di delivery/manutenzione dei servizi [AWS]. In questi contesti la GenAI può essere utilizzata anche per generare in automatico riassunti di telefonate o di conversazioni piuttosto che e-mail di recap/follow-up da inviare come reminder ai clienti che hanno contattato l’assistenza o ai prospect che si sono informati su caratteristiche di prodotti o servizi. Un case molto popolare nel mondo Telco [AWS] [Acc] è quello dei chatbot, che prevede di esporre direttamente al cliente finale un’interfaccia conversazionale, come già si fa da anni. La differenza sta nel fatto che oggi il motore che genera le risposte del bot può essere un LLM e quindi capace di migliorate capacità di comprensione ed efficacia nelle risposte, al prezzo di un rischio di generazione di risposte non sempre corrette.
Code Generation for IT
In questo caso modelli LLM specializzati nella generazione del codice, come Codex di OpenAI, usato da GitHub Copilot, assistono i programmatori in vari task legati allo sviluppo e alla manutenzione del codice: code generation, debugging, refactoring, spiegazione e documentazione del codice, generazione di test automatici [AWS]. Le previsioni più ottimistiche sbandierano un vertiginoso 100% di incremento nella produttività (“twice as fast”) di chi scrive codice [McK]. Va osservato che, anche se venissero raggiunte queste vette, tuttavia le attività IT nel perimetro delle grandi aziende solo in parte si declinano in task di scrittura/evoluzione/ manutenzione del codice e comprendono, invece, e forse per la maggior parte, attività sicuramente più difficili da automatizzare legate alla gestione delle risorse, al coordinamento, alla stesura ed evoluzione delle specifiche e dei sistemi legacy e integrazioni che ne derivano.
Enhanced Data Analysis
Questo caso prevede che la GenAI venga usata per assistere le attività dei Data Analyst. Ad oggi, tipicamente, i Data Analyst hanno a disposizione degli ambienti analitici, come SAS, dove impostano delle query in linguaggi specializzati al fine di ottenere risposte a domande di business e insight di valore. La promessa della GenAI, in questo ambito, è quella di poter chiedere le risposte che si desiderano in linguaggio naturale, ottenendo risposte in forma di narrazione, di grafici o direttamente di report completi. Esistono plugin per ChatGPT specializzati nella generazione di SQL a partire da domande poste in linguaggio naturale, così come vari strumenti di BI ormai da tempo offrono capability di interrogazione in linguaggio naturale.
Generazione di contenuti creativi e iper-personalizzati
In questo caso i modelli generativi, non solo del linguaggio, ma soprattutto di immagini e video, quali DALL-E, Stable Diffusion e MidJourney, vengono utilizzati per creare immagini e contenuti testuali (copy) adatti alle esigenze di marketing o di caring [Acc]. I contenuti possono anche essere adattati alle caratteristiche del singolo cliente. Va osservato che questo tipo di attività porta con sé il rischio di incorrere in problemi di copyright infringement. Sono ormai all’ordine del giorno le cause intentate da famosi artisti a OpenAI per violazione dei diritti di copyright.
AI for AI
Si tratta di use case dove le capability di comprensione e processamento di Large Language Model vengono utilizzate al servizio di altri algoritmi di Intelligenza Artificiale, quali clustering, classificazione, recommendation, Natural Language Processing, Sentiment Analysis, Anonymization, pulizia dei dati.
Learning and re-skilling
Questo use case mira a fornire ai dipendenti strumenti a supporto dell’acquisizione di nuove competenze o aggiornamento di knowledge già appresa. Mediante l’interfaccia conversazionale un argomento da apprendere può essere affrontato in maniera personalizzata: l’utente può fare domande dal proprio punto di vista e anche dichiarando esplicitamente quali sono le proprie competenze di partenza; ad esempio: “Tieni conto che sono uno sviluppatore software esperto nel linguaggio Java e sto imparando Python; come faccio, in Python, a realizzare un programma parallelo? Quali librerie conviene usare? Quali sono gli idiomi tipici?”. Oppure l’IA può simulare il comportamento di un cliente che chiede assistenza su un certo argomento per abilitare nuove forme di training per gli operatori [Acc].
Generazione di dati sintetici
Questo caso d’uso prevede la generazione di dati finti, ma aventi le stesse caratteristiche statistiche di un certo dataset di partenza. In questo modo, i dati sintetici generati sono privi della presenza di dati personali e/o sensibili e possono essere utilizzati per addestrare modelli di Machine Learning con vincoli di privacy e compliance meno stringenti. Può essere il caso di modelli addestrati a partire dalle note degli Operatori piuttosto che dai dati di traffico dei clienti sulla rete.
Benefici
Ottimizzazione effort e costi
Il principale beneficio che viene sbandierato da tutti i sostenitori della rivoluzione della GenAI consiste nell’aumento della produttività dei lavoratori, nello specifico dei cosiddetti Knowledge Worker. Come conseguenza gli operatori e tecnici potranno dedicare il proprio tempo alla risoluzione delle problematiche più complesse e che non siano catturate nell’ambito delle procedure codificate, consentendo una miglior Customer Satisfaction dal punto di vista del cliente e una miglior Quality of Service della Rete. Ci si attende che le versioni future dei pacchetti di Office Automation (Teams, Office, Google Suite, etc.) integreranno strumenti di GenAI per abilitare scenari quali il riassunto automatico dei meeting, la ricerca conversazionale sui documenti presenti nella propria area personale oppure sull’intera Intranet, velocizzando procedimenti e ricerche che, ad oggi, risultano essere molto time-consuming.
Revenue Generation
La capacità di adattarsi alle caratteristiche dei clienti anche nel linguaggio e nel modo di porsi possono facilitare operazioni di upselling, cross-selling e Next Best Offer. La dimensione dell’incremento dei ricavi è impattata positivamente anche dall’aumentata capacità di produrre analisi e/o modelli analitici performanti.
Incremento della Customer Satisfaction e della Quality of Service
Clienti serviti in modo più efficace saranno più soddisfatti. Inoltre, gli strumenti abilitati dalla GenAI a supporto dell’operatività dei tecnici sulla rete ne determinerà un aumento della QoS di Rete. Anche la CS e la QoS, come la Revenue Generation, beneficiano della accelerata disponibilità di analisi e modelli ottenuta grazie all’applicazione della GenAI.
Standardizzazione delle risposte verso i Customer
Un effetto collaterale positivo dell’adozione di questi strumenti, per fornire risposte ai clienti, anche se non esclusivo della GenAI, è la standardizzazione delle risposte date ai clienti. Ad oggi, laddove i clienti si interfacciano con operatori human per la risoluzione delle proprie problematiche relative a prodotti e servizi dell’azienda, possono talvolta incappare in risposte che variano a seconda dell’operatore, per questioni di varietà di conoscenze e di skill. La generazione di risposte verso il cliente da parte di strumenti di GenAI produrrà risposte maggiormente standardizzate e univoche dal punto di vista concettuale, anche se diverse di volta in volta.
Acquisizione di Know-How
Utilizzando strumenti della AI generativa “addestrati” su documentazione, manualistica e anche, dove applicabile, su passate interazioni operatore/cliente o lavorazioni di Operations, i lavoratori potranno acquisire più velocemente il know-how necessario ad affrontare le varie situazioni lavorative in modalità personalizzata ed adeguata al proprio livello di conoscenza.
Ostacoli all’adozione
Allucinazioni, logica fallace e rischi di Prompt Injection
Sono celeberrimi i casi di allucinazioni di ChatGPT: il modello, infatti, è stato addestrato per rispondere nel modo più probabile alle domande degli utenti, con, ovviamente, un pizzico di varietà. Il modello non è stato, invece, addestrato per essere corretto o fattuale nelle risposte che fornisce. Da qui scaturiscono i casi in cui le riposte generate, pur essendo molto verosimili e convincenti, tuttavia, a una più attenta analisi, si rivelano false. Ne discende la necessità di adottare le soluzioni di GenAI in ambiti vincolati e monitorati, al fine di misurare e prevenire/mitigare i casi di allucinazioni. La fase di monitoring non può che essere svolta da persone esperte del dominio. Va osservato che, nel caso in cui si sviluppino applicazioni customer-facing, senza mediazione tra quanto prodotto dalla GenAI e il cliente finale, esiste un rischio di generazione di allucinazioni e, quindi, un rischio reputazionale per l’azienda. Ad oggi, la stessa OpenAI suggerisce di non sviluppare applicazioni direttamente affacciateverso il cliente, ma di prevedere sempre l’intermediazione di un esperto [OAI]. I modelli LLM sono molto bravi nel fare delle semplici deduzioni a partire da pochi semplici fatti. Questo è un loro punto di forza grandissimo, che abilita la capacità di rispondere a domande non banali. Tuttavia, quando la difficoltà delle domande aumenta e inizia a richiedere deduzioni complesse, aggregazioni di dati o computazioni, allora si manifestano abbastanza spesso episodi in cui la capacità di reasoning dell’LLM risulta fallace. Esistono delle tecniche per mitigare questo effetto (es.: Chain-of-Thought) e sono possibili integrazioni con strumenti esterni per sopperire, ad esempio, alle scarse capacità di computazione degli LLM. Anche in questo caso è richiesto un rigoroso e costante controllo human, ancorché necessariamente a campione, per comprendere i limiti della tecnologia e tarare il giusto equilibrio tra le sue capability e quanto si offre/ vende ai clienti o agli utilizzatori interni. Nel caso di applicazioni customer-facing esiste la concreta possibilità che utenti malintenzionati cerchino di piegare il comportamento dei modelli LLM e costringerli a bypassare i vincoli di buona condotta imposti dai fornitori dei foundation model (cosiddetto hijacking). In questi casi, esiste un rischio reputazionale dell’azienda che potrebbe vedere i propri chatbot generare contenuti scorretti o drammaticamente inadeguati.
Compliance , Security & Privacy
Molti degli use case di maggior valore richiedono che comunicazioni dei clienti con l’azienda e/o testo prodotto dai dipendenti e trascrizioni di riunioni siano elaborati da parte dei modelli LLM. La fattibilità normativa di tali elaborazioni va concordata con le funzioni di Security, Privacy e Compliance, anche tenendo conto del fatto che si tratta di servizi forniti esclusivamente in cloud dai vari Microsoft, Google, etc. Attenzione, inoltre, all’imminente AI Act [EU], che regolamenterà l’uso dell’AI in ambito europeo, con finalità di protezione della privacy dei cittadini e di utilizzo etico della tecnologia.
Costi di Consumption, Markup e Maintenance
Ovviamente i servizi dei modelli di GenAI hanno un costo, tipicamente basato su misure di consumo da corrispondere ai fornitori di foundation model. Oltre a tali costi, nel caso in cui ci si affidasse a soluzioni costruite on top degli LLM di base, ci sarebbe da corrispondere il markup richiesto dal fornitore di servizi di turno. [Squ] Inoltre, occorre provvedere all’organizzazione e alla spesatura di monitoraggi continui, a campione, e di maintenance per far fronte a cambiamenti che sicuramente avverranno nel tempo a livello di comportamento dei modelli foundation: i vendor si stanno attrezzando per offrire Long Term Support per almeno un sott’insieme dei LLM, ma gli orizzonti temporali visibili ad oggi sono di circa un anno di disponibilità garantita [Azu]; dopodiché il modello di base cambierà e tutte le applicazioni costruite on top ne potrebbero risentire.
Rischi di copyright infringement
Come già accennato, esiste il rischio che il contenuto generato dai modelli GenAI possa violare i diritti d’autore. In molti casi, per ora in ambito USA, i fornitori di foundation model sono stati chiamati in causa in tribunale per difendere il proprio operato [Wir].
Bias & Ethics
Altro rischio di tipo reputazionale per l’azienda, pur non essendo esclusivo dei modelli di GenAI, consiste nella possibilità che emergano nei contenuti prodotti i cosiddetti bias dei modelli foundation, legati a differenze, presenti nei documenti usati per il training iniziale dei modelli stessi, collegate al genere, al perimetro culturale di appartenenza, alle opinioni politiche, etc. Anche questo rischio può essere monitorato, campionando le conversazioni con le intelligenze artificiali ed eventualmente adoperandosi in modo proattivo per far emergere le problematiche per poi indirizzarle. Va riconosciuto che gli stessi fornitori di modelli foundation si adoperano da tempo per ingabbiare il comportamento dei modelli stessi in regole/meccanismi volti ad evitare comportamenti non fair.