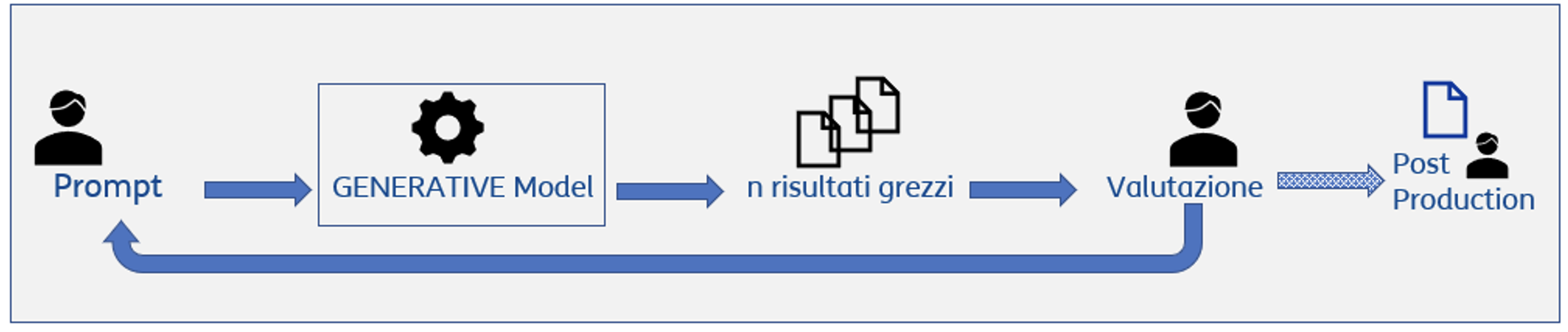
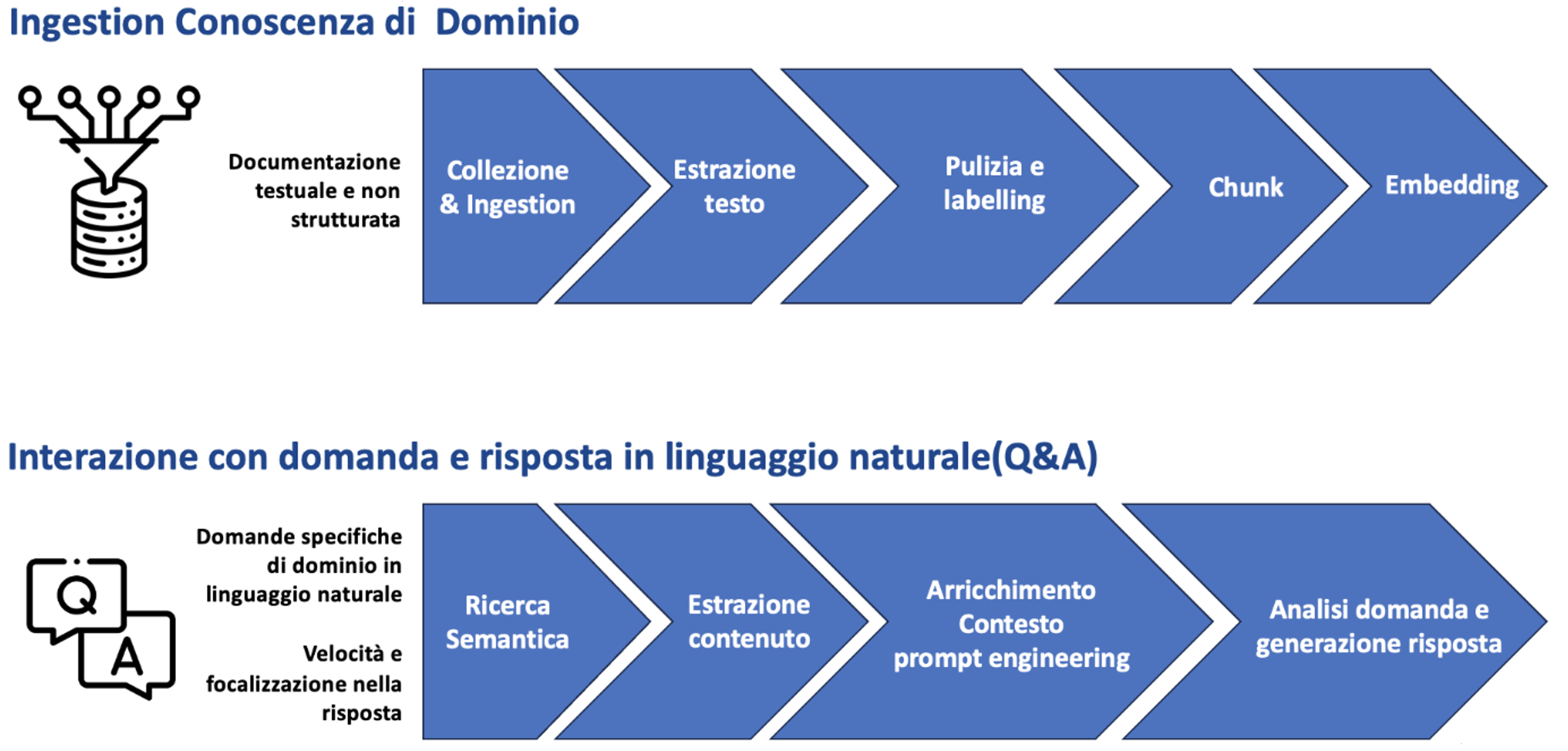
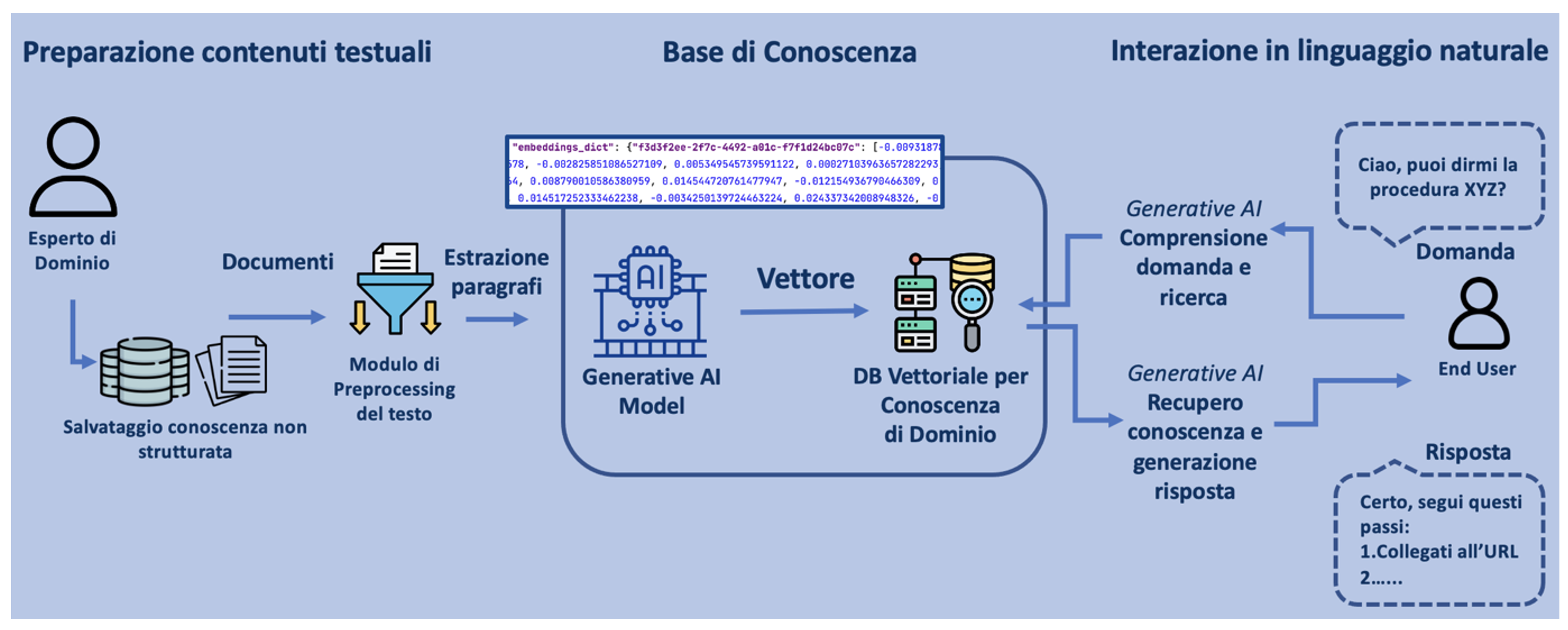
Con l’avvento di ChatGPT nel novembre 2022 si è diffusa l’idea che possa esistere un’Intelligenza Artificiale generale in grado di automatizzare compiti, fornire idee creative e persino scrivere software, sia per aziende che per consumatori. ChatGPT, acronimo di Chatbot Generative Pre-trained Transformer, si basa su un modello di AI ovvero un Large Language Model, nella fattispecie GPT [8, 9], addestrato su grandi quantità di testo al fine di comprendere e generare testo coerente. Un ruolo fondamentale nel campo del Natural Language Processing (NLP) è legato ai Transformers in quanto modelli di apprendimento automatico in grado di “catturare” le relazioni complesse tra parole e concetti. Questi modelli, introdotti nel 2017 nell’articolo “Attention Is All You Need” [2], sono alla base del Generative Pre-trained Transformer (GPT) e sono composti da due componenti principali: l’encoder, che codifica l’input in una rappresentazione vettoriale numerica comprensiva delle relazioni tra parti del testo, e il decoder, che genera l’output basato su questa rappresentazione per produrre un testo coerente con il significato dell’input. I pre-trained transformers hanno permesso di superare le difficoltà di codifica delle parti lessicali, sintattiche, grammaticali, etc… grazie alla capacità di apprendere automaticamente le relazioni tra le parti dei dati in input, detti Token. Sarà quindi il Token l’unità fondamentale per: la trasformazione del testo in vettori di numeri, embeddings; il fine tuning ovvero addestramento su aspetti specifici; il prompting, istruzione data per la generazione del testo desiderato; la completion ovvero il con tenuto generato. Il modello matematico lavorerà sui token di cui è costituito l’input per apprendere e genererà il risultato fornendo una successione di token su base probabilistica/stocastica. In questo senso il modello di generative AI e GPT nella fattispecie non sono “consapevoli” della bontà del contenuto generato seppur plausibile e grammaticalmente corretto. Il prompt engineering si configura quindi come una nuova disciplina per assicurare controllo e correttezza tra quanto si desidera ottenere ed il risultato fornito dal modello. Fake e allucinazioni mascherate dalla plausibilità del testo generato devono quindi essere un punto di forte attenzione ai fini dell’utilizzo professionale e quotidiano di questi sistemi di Intelligenza Artificiale. Nell’era del prompt, dunque, saper fare le domande diviene una competenza determinante, perché si passa dalla ricerca delle informazioni corrette, alla formazione della corretta ricerca. Nasce, così, la cosiddetta promptologia, cioè la nuova abilità ingegneristica di ideare domande per spingere l’Intelligenza Artificiale a fornire risposte appropriate che richiede anche la comprensione del linguaggio e dell’espressione. A valle di questa veloce disamina degli elementi tecnico – scientifici alla base della Generative AI, possiamo dire che i Large Language Models (LLM) come GPT possono essere sfruttati come:
- un mezzo per dialogare in linguaggio naturale con una macchina, e quindi come strumento di interazione uomomacchina per comunicare in linguaggio naturale;
- come strumento di una Intelligenza Artificiale generale che, se addestrata costantemente e su grande quantità di dati, può indurci a immaginare la nascita di un’entità senziente o per lo meno in grado di generare informazione plausibile, ma non necessariamente corretta data la natura statistica di questa generazione.